高性能
高性能
数据库读写分离
根据读写分离的名字,我们就可以知道:读写分离主要是为了将对数据库的读写操作分散到不同的数据库节点上。 这样的话,就能够小幅提升写性能,大幅提升读性能。
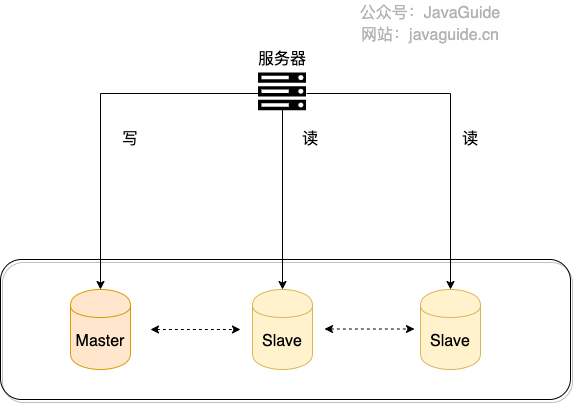
读写分离对于提升数据库的并发非常有效,但是,同时也会引来一个问题:主库和从库的数据存在延迟,比如你写完主库之后,主库的数据同步到从库是需要时间的,这个时间差就导致了主库和从库的数据不一致性问题。这也就是我们经常说的 主从同步延迟 。
1.强制将读请求路由到主库处理。
2.延迟读取。
分库分表
读写分离主要应对的是数据库读并发,没有解决数据库存储问题。试想一下:如果 MySQL 一张表的数据量过大怎么办?
答案之一就是 分库分表。
分库 就是将数据库中的数据分散到不同的数据库上。
下面这些操作都涉及到了分库:
- 你将数据库中的用户表和用户订单表分别放在两个不同的数据库。
- 由于用户表数据量太大,你对用户表进行了水平切分,然后将切分后的 2 张用户表分别放在两个不同的数据库。
分表 就是对单表的数据进行拆分,可以是垂直拆分,也可以是水平拆分。
何为垂直拆分?
简单来说,垂直拆分是对数据表列的拆分,把一张列比较多的表拆分为多张表。
何为水平拆分?
简单来说,水平拆分是对数据表行的拆分,把一张行比较多的表拆分为多张表。
CDN
CDN 全称是 Content Delivery Network/Content Distribution Network,翻译过的意思是 内容分发网络 。
我们可以将内容分发网络拆开来看:
- 内容 :指的是静态资源比如图片、视频、文档、JS、CSS、HTML。
- 分发网络 :指的是将这些静态资源分发到位于多个不同的地理位置机房中的服务器上,这样,就可以实现静态资源的就近访问比如北京的用户直接访问北京机房的数据。
所以,简单来说,CDN 就是将静态资源分发到多个不同的地方以实现就近访问,进而加快静态资源的访问速度,减轻服务器以及带宽的负担。绝大部分公司都会在项目开发中交使用 CDN 服务,但很少会有自建 CDN 服务的公司。基于成本、稳定性和易用性考虑
如何找到最合适的 CDN 节点?
GSLB (Global Server Load Balance,全局负载均衡是 CDN 的大脑,负责多个CDN节点之间相互协作,最常用的是基于 DNS 的 GSLB。
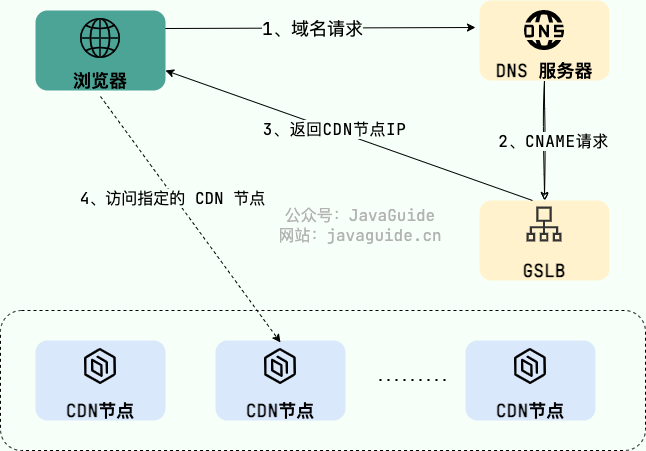
CDN 会通过 GSLB 找到最合适的 CDN 节点,更具体点来说是下面这样的:
- 浏览器向 DNS 服务器发送域名请求;
- DNS 服务器向根据 CNAME( Canonical Name ) 别名记录向 GSLB 发送请求;
- GSLB 返回性能最好(通常距离请求地址最近)的 CDN 节点(边缘服务器,真正缓存内容的地方)的地址给浏览器;
- 浏览器直接访问指定的 CDN 节点。
负载均衡
高可用
冗余
冗余设计是保证系统和数据高可用的最常的手段。
对于服务来说,冗余的思想就是相同的服务部署多份,如果正在使用的服务突然挂掉的话,系统可以很快切换到备份服务上,大大减少系统的不可用时间,提高系统的可用性。对于数据来说,冗余的思想就是相同的数据备份多份,这样就可以很简单地提高数据的安全性。
高可用集群(High Availability Cluster,简称 HA Cluster)、同城灾备、异地灾备、同城多活和异地多活是冗余思想在高可用系统设计中最典型的应用。
- 高可用集群 : 同一份服务部署两份或者多份,当正在使用的服务突然挂掉的话,可以切换到另外一台服务,从而保证服务的高可用。
- 同城灾备 :一整个集群可以部署在同一个机房,而同城灾备中相同服务部署在同一个城市的不同机房中。并且,备用服务不处理请求。这样可以避免机房出现意外情况比如停电、火灾。
- 异地灾备 :类似于同城灾备,不同的是,相同服务部署在异地(通常距离较远,甚至是在不同的城市或者国家)的不同机房中
- 同城多活 :类似于同城灾备,但备用服务可以处理请求,这样可以充分利用系统资源,提高系统的并发。
- 异地多活 : 将服务部署在异地的不同机房中,并且,它们可以同时对外提供服务。
举个例子:哨兵模式的 Redis 集群中,如果 Sentinel(哨兵) 检测到 master 节点出现故障的话, 它就会帮助我们实现故障转移,自动将某一台 slave 升级为 master,确保整个 Redis 系统的可用性。整个过程完全自动,不需要人工介入。
再举个例子: Nginx 可以结合 Keepalived 来实现高可用。如果 Nginx 主服务器宕机的话,Keepalived 可以自动进行故障转移,备用 Nginx 主服务器升级为主服务。并且,这个切换对外是透明的,因为使用的虚拟 IP,虚拟 IP 不会改变。
限流
固定窗口计数器算法
针对软件系统来说,限流就是对请求的速率进行限制,避免瞬时的大量请求击垮软件系统。固定窗口其实就是时间窗口。固定窗口计数器算法 规定了我们单位时间处理的请求数量。
滑动窗口计数器算法
滑动窗口计数器算法相比于固定窗口计数器算法的优化在于:它把时间以一定比例分片 。例如我们的接口限流每分钟处理 60 个请求,我们可以把 1 分钟分为 60 个窗口。每隔 1 秒移动一次,每个窗口一秒只能处理 不大于 60(请求数)/60(窗口数) 的请求, 如果当前窗口的请求计数总和超过了限制的数量的话就不再处理其他请求。
漏桶算法
我们可以把发请求的动作比作成注水到桶中,我们处理请求的过程可以比喻为漏桶漏水。我们往桶中以任意速率流入水,以一定速率流出水。当水超过桶流量则丢弃,因为桶容量是不变的,保证了整体的速率。如果想要实现这个算法的话也很简单,准备一个队列用来保存请求,然后我们定期从队列中拿请求来执行就好了(和消息队列削峰/限流的思想是一样的)。
令牌桶算法
令牌桶算法也比较简单。和漏桶算法算法一样,不过现在桶里装的是令牌了,请求在被处理之前需要拿到一个令牌,请求处理完毕之后将这个令牌丢弃(删除)。我们根据限流大小,按照一定的速率往桶里添加令牌。如果桶装满了,就不能继续往里面继续添加令牌了。
超时重传
什么是超时机制?
超时机制说的是当一个请求超过指定的时间(比如 1s)还没有被处理的话,这个请求就会直接被取消并抛出指定的异常或者错误(比如 504 Gateway Timeout)。我们平时接触到的超时可以简单分为下面 2 种:
- 连接超时(ConnectTimeout) :客户端与服务端建立连接的最长等待时间。
- 读取超时(ReadTimeout) :客户端和服务端已经建立连接,客户端等待服务端处理完请求的最长时间。实际项目中,我们关注比较多的还是读取超时。
一些连接池客户端框架中可能还会有获取连接超时和空闲连接清理超时。如果没有设置超时的话,就可能会导致服务端连接数爆炸和大量请求堆积的问题。这些堆积的连接和请求会消耗系统资源,影响新收到的请求的处理。严重的情况下,甚至会拖垮整个系统或者服务。
我之前在实际项目就遇到过类似的问题,整个网站无法正常处理请求,服务器负载直接快被拉满。后面发现原因是项目超时设置错误加上客户端请求处理异常,导致服务端连接数直接接近 40w+,这么多堆积的连接直接把系统干趴了。
什么是重试机制?
重试机制一般配合超时机制一起使用,指的是多次发送相同的请求来避免瞬态故障和偶然性故障。瞬态故障可以简单理解为某一瞬间系统偶然出现的故障,并不会持久。偶然性故障可以理解为哪些在某些情况下偶尔出现的故障,频率通常较低。 重试的核心思想是通过消耗服务器的资源来尽可能获得请求更大概率被成功处理。由于瞬态故障和偶然性故障是很少发生的,因此,重试对于服务器的资源消耗几乎是可以被忽略的。
重试幂等
超时和重试机制在实际项目中使用的话,需要注意保证同一个请求没有被多次执行。什么情况下会出现一个请求被多次执行呢?客户端等待服务端完成请求完成超时但此时服务端已经执行了请求,只是由于短暂的网络波动导致响应在发送给客户端的过程中延迟了。
举个例子:用户支付购买某个课程,结果用户支付的请求由于重试的问题导致用户购买同一门课程支付了两次。对于这种情况,我们在执行用户购买课程的请求的时候需要判断一下用户是否已经购买过。这样的话,就不会因为重试的问题导致重复购买了。





