SpringCloud
微服务相关概念
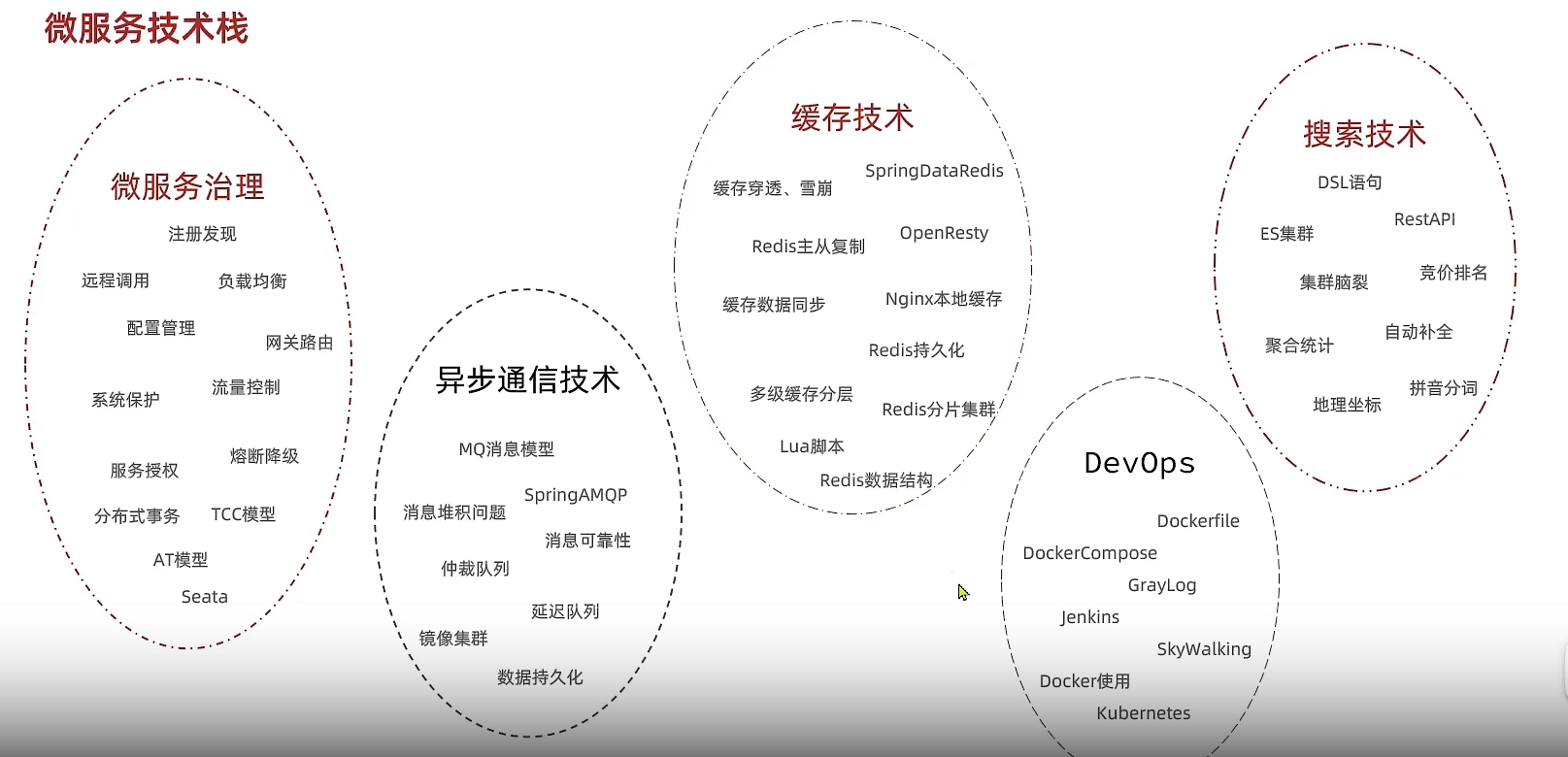
微服务需要根据业务模块进行拆分,做到单一职责,不要重复开发
微服务可以将自己的服务暴露为接口,供其他服务使用
不同的微服务应该有不同的数据库

Spring Cloud简介
Spring Cloud是一系列框架的有序集合。它利用Spring Boot的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等,都可以用Spring Boot的开发风格做到一键启动和部署。Spring并没有重复制造轮子,它只是将目前各家公司开发的比较成熟、经得起实际考验的服务框架组合起来,通过Spring Boot风格进行再封装屏蔽掉了复杂的配置和实现原理,最终给开发者留出了一套简单易懂、易部署和易维护的分布式系统开发工具包。
核心成员
Spring Cloud Netflix套件
参考:Spring Cloud Netflix 中文文档 参考手册 中文版
Netflix Eureka
Eureka是Netflix开发的服务发现框架,本身是一个基于REST的服务,主要用于定位运行在AWS域中的中间层服务,以达到负载均衡和中间层服务故障转移的目的。
Netflix Hystrix
熔断器,容错管理工具,旨在通过熔断机制控制服务和第三方库的节点,从而对延迟和故障提供更强大的容错能力。
Netflix Zuul
Zuul 是在云平台上提供动态路由,监控,弹性,安全等边缘服务的框架。Zuul 相当于是设备和 Netflix 流应用的 Web 网站后端所有请求的前门。
Netflix Ribbon
Ribbon is a client side IPC library that is battle-tested in cloud. It provides the following features,Load balancing,Fault tolerance,Multiple protocol (HTTP, TCP, UDP) support in an asynchronous and reactive model,Caching and batching
Netflix Feign
feign是声明式的web service客户端,它让微服务之间的调用变得更简单了,类似controller调用service。Spring Cloud集成了Ribbon和Eureka,可在使用Feign时提供负载均衡的http客户端。
Spring Cloud Alibaba套件
Nacos
Nacos 致力于帮助您发现、配置和管理微服务。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据及流量管理。 Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。 Nacos 是构建以“服务”为中心的现代应用架构 (例如微服务范式、云原生范式) 的服务基础设施。
Sentinel
Sentinel的官方标题是:分布式系统的流量防卫兵。从名字上来看,很容易就能猜到它是用来作服务稳定性保障的。对于服务稳定性保障组件,如果熟悉Spring Cloud的用户,第一反应应该就是Hystrix。但是比较可惜的是Netflix已经宣布对Hystrix停止更新。那么,在未来我们还有什么更好的选择呢?除了Spring Cloud官方推荐的resilience4j之外,目前Spring Cloud Alibaba下整合的Sentinel也是用户可以重点考察和选型的目标。
Spring Cloud原生及其他整合组件
CAP理论
CAP 理论是针对分布式数据库而言的,它是指在一个分布式系统中,一致性(Consistency, C)、可用性(Availability, A)、分区容错性(Partition Tolerance, P)三者不可兼得。
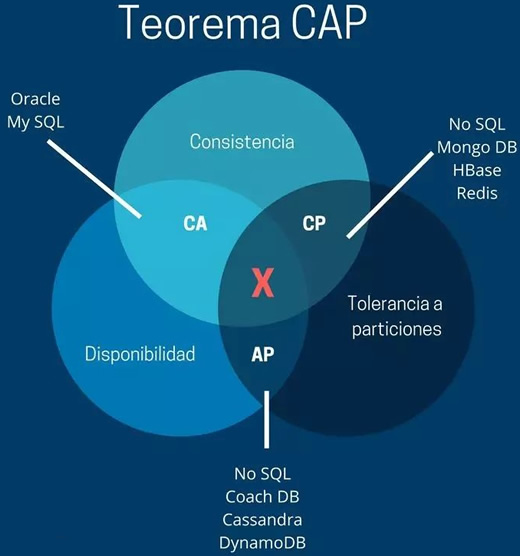
一致性(C)
一致性是指“all nodes see the same data at the same time”,即更新操作成功后,所有节点在同一时间的数据完全一致。
一致性可以分为客户端和服务端两个不同的视角:
- 从客户端角度来看,一致性主要指多个用户并发访问时更新的数据如何被其他用户获取的问题;
- 从服务端来看,一致性则是用户进行数据更新时如何将数据复制到整个系统,以保证数据的一致。
一致性是在并发读写时才会出现的问题,因此在理解一致性的问题时,一定要注意结合考虑并发读写的场景。
可用性(A)
可用性是指“reads and writes always succeed”,即用户访问数据时,系统是否能在正常响应时间返回结果。
好的可用性主要是指系统能够很好地为用户服务,不出现用户操作失败或者访问超时等用户体验不好的情况。在通常情况下,可用性与分布式数据冗余、负载均衡等有着很大的关联。
分区容错性(P)
分区容错性是指“the system continues to operate despite arbitrary message loss or failure of part of the system”,即分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。
分区容错性和扩展性紧密相关。在分布式应用中,可能因为一些分布式的原因导致系统无法正常运转。分区容错性高指在部分节点故障或出现丢包的情况下,集群系统仍然能提供服务,完成数据的访问。分区容错可视为在系统中采用多副本策略。
Eureka
概念
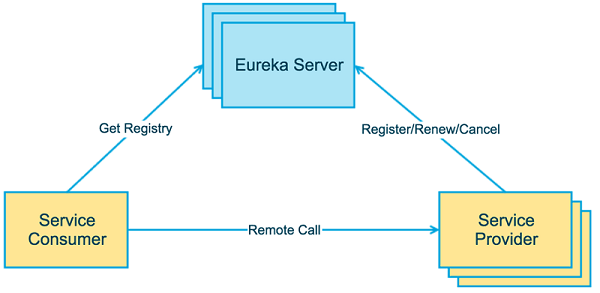
服务发现是基于微服务架构的关键原则之一。尝试配置每个客户端或某种形式的约定可能非常困难,可能非常脆弱。Netflix服务发现服务器和客户端是Eureka。可以将服务器配置和部署为高可用性,每个服务器将注册服务的状态复制到其他服务器。
考虑当前有两个微服务实例A和B,A服务需要调用B服务的某个REST接口。假如某一天B服务迁移到了另外一台服务器,IP和端口也发生了变化,这时候我们不得不去修改A服务中调用B服务REST接口的静态配置。随着公司业务的发展,微服务的数量也越来越多,服务间的关系可能变得非常复杂,传统的微服务维护变得愈加困难,也很容易出错。所谓服务治理就是用来实现各个微服务实例的自动化注册与发现,在这种模式下,服务间的调用不再通过指定具体的实例地址来实现,而是通过向服务注册中心获取服务名并发起请求调用实现。
Eureka是由Netflix开发的一款服务治理开源框架,Spring-cloud对其进行了集成。Eureka既包含了服务端也包含了客户端,Eureka服务端是一个**服务注册中心(Eureka Server),提供服务的注册和发现,即当前有哪些服务注册进来可供使用;Eureka客户端为服务提供者(Server Provider),它将自己提供的服务注册到Eureka服务端,并周期性地发送心跳来更新它的服务租约,同时也能从服务端查询当前注册的服务信息并把它们缓存到本地并周期性地刷新服务状态。这样服务消费者(Server Consumer)**便可以从服务注册中心获取服务名称,并消费服务。
Eureka的自我保护机制
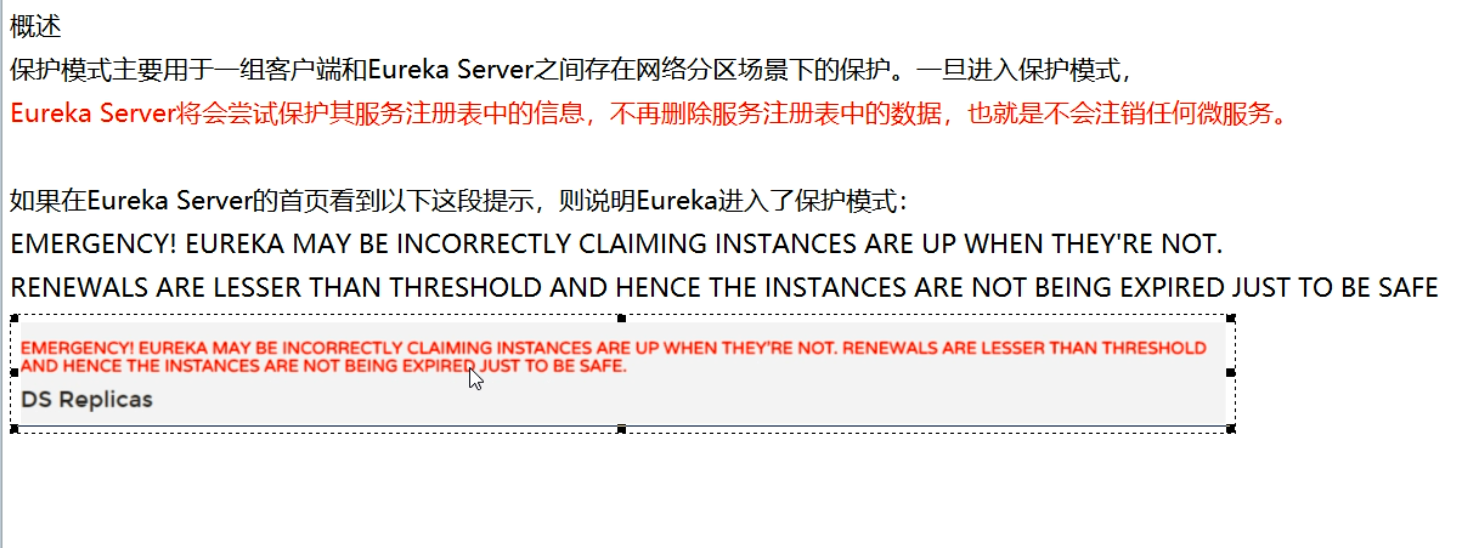
一句话:某时刻某一个微服务不可用了,Eureka不会立刻清理,依旧会对该微服务的信息进行保存,属于CAP的AP分支
参考:Spring Cloud Eureka服务治理 | MrBird
consul
参考:Spring Cloud Consul 中文文档 参考手册 中文版
Consul 是 HashiCorp 公司推出的开源工具,用于实现分布式系统的服务发现与配置。与其他分布式服务注册与发现的方案,Consul 的方案更“一站式”,内置了服务注册与发现框 架、分布一致性协议实现、健康检查、Key/Value 存储、多数据中心方案,不再需要依赖其他工具(比如 ZooKeeper 等)。使用起来也较 为简单。Consul 使用 Go 语言编写,因此具有天然可移植性(支持Linux、windows和Mac OS X);安装包仅包含一个可执行文件,方便部署,与 Docker 等轻量级容器可无缝配合。
使用 Raft 算法来保证一致性, 比复杂的 Paxos 算法更直接. 相比较而言, zookeeper 采用的是 Paxos, 而 etcd 使用的则是 Raft。
支持多数据中心,内外网的服务采用不同的端口进行监听。 多数据中心集群可以避免单数据中心的单点故障,而其部署则需要考虑网络延迟, 分片等情况等。 zookeeper 和 etcd 均不提供多数据中心功能的支持。
支持健康检查。 etcd 不提供此功能。
支持 http 和 dns 协议接口。 zookeeper 的集成较为复杂, etcd 只支持 http 协议。
官方提供 web 管理界面, etcd 无此功能。
综合比较, Consul 作为服务注册和配置管理的新星, 比较值得关注和研究。
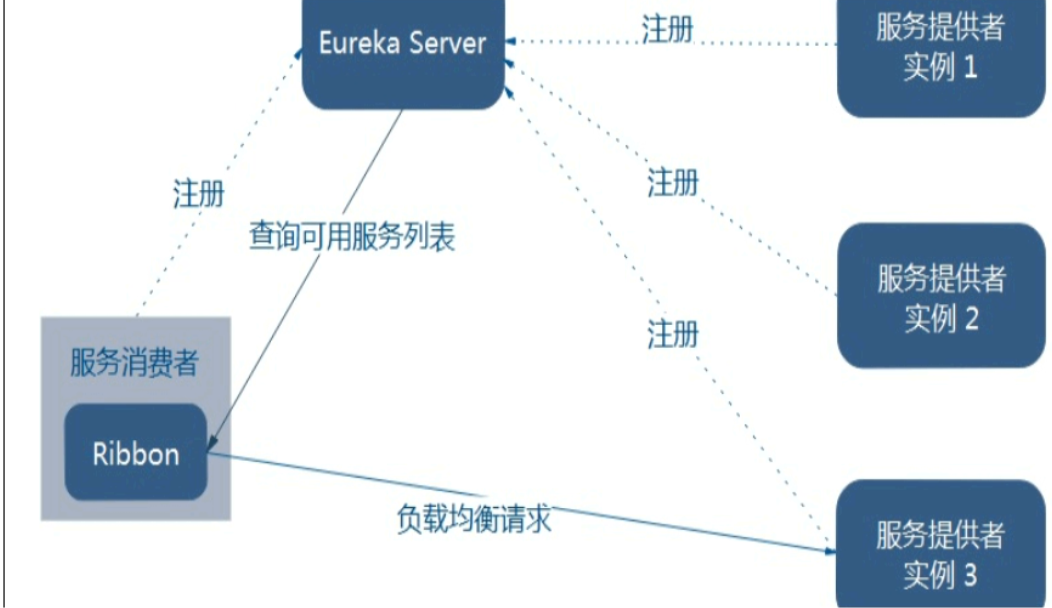
Ribbon详解
Spring Cloud Ribbon是一个基于HTTP和TCP的客户端负载均衡工具,它基于Netflix Ribbon实现。通过Spring Cloud的封装,可以让我们轻松地将面向服务的REST模版请求自动转换成客户端负载均衡的服务调用。Spring Cloud Ribbon虽然只是一个工具类框架,它不像服务注册中心、配置中心、API网关那样需要独立部署,但是它几乎存在于每一个Spring Cloud构建的微服务和基础设施中。因为微服务间的调用,API网关的请求转发等内容,实际上都是通过Ribbon来实现的,包括后续我们将要介绍的Feign,它也是基于Ribbon实现的工具。所以,对Spring Cloud Ribbon的理解和使用,对于我们使用Spring Cloud来构建微服务非常重要。
而客户端负载均衡和服务端负载均衡最大的不同点在于上面所提到服务清单所存储的位置。在客户端负载均衡中,所有客户端节点都维护着自己要访问的服务端清单,而这些服务端端清单来自于服务注册中心
openFeign
Feign
Feign 是一个声明式 WebService 客户端。使用 Feign 能让编写 Web Service 客户端更加简单。Feign集成了Ribbon、RestTemplate实现了负载均衡的执行Http调用,只不过对原有的方式(Ribbon+RestTemplate)进行了封装,开发者不必手动使用RestTemplate调服务,而是定义一个接口,在这个接口中标注一个注解即可完成服务调用,这样更加符合面向接口编程的宗旨,简化了开发。
它的使用方法是定义一个服务接口然后在上面添加注解。Feign 也支持可拔插式的编码器和解码器。Spring Cloud 对 Feign 进行了封装,使其支持了 Spring MVC 标准注解和 HttpMessageConverters。Feign 可以与 Eureka 和 Ribbon 组合使用以支持负载均衡;

OpenFeign日志级别:

断路器:Hystrix
中文文档:http://t.zoukankan.com/flashsun-p-12579367.html
Hystrix概念
在分布式环境中,众多的服务依赖中有一些不可避免地会失败。Hystrix是一个库,通过添加延迟容忍和容错逻辑,帮助您控制这些分布式服务之间的交互。Hystrix通过隔离服务之间的访问点、阻止跨服务的级联故障以及提供回退选项来实现这一点,所有这些都可以提高系统的整体弹性。
Hystrix的设计目的如下:
- 引入第三方的 client 类库,通过延迟与失败的检测,来保护服务与服务之间的调用(网络间调用最为典型)
- 停止复杂分布式系统中的级联故障。
- 快速失败与快速恢复机制
- 提供兜底方案(fallback)并在适当的时机优雅降级
- 启用近实时监控、警报和操作控制。
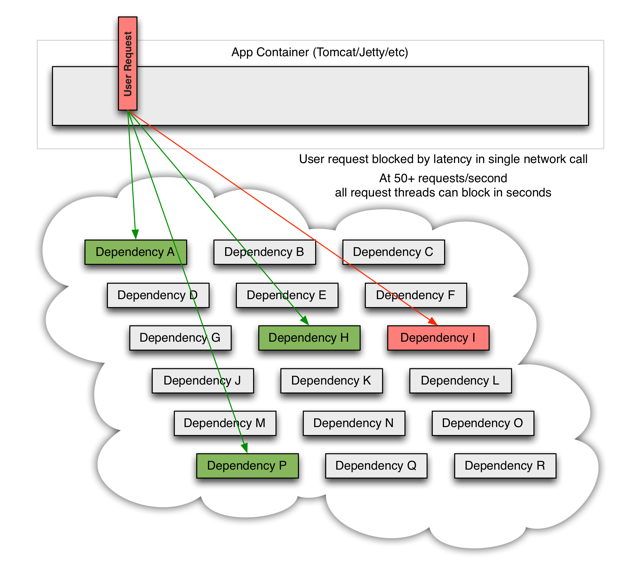
When one of many backend systems becomes latent it can block the entire user request:
当一个依赖的节点坏掉时,将阻塞整个的用户请求:
With high volume traffic a single backend dependency becoming latent can cause all resources to become saturated in seconds on all servers.
Every point in an application that reaches out over the network or into a client library that might result in network requests is a source of potential failure. Worse than failures, these applications can also result in increased latencies between services, which backs up queues, threads, and other system resources causing even more cascading failures across the system.
流量高峰时,一个单节点的宕机或延迟,会迅速导致所有服务负载达到饱和。应用中任何一个可能通过网络访问其他服务的节点,都有可能成为造成潜在故障的来源。更严重的是,还可能导致服务之间的延迟增加,占用队列、线程等系统资源,从而导致多系统之间的级联故障。
These issues are exacerbated when network access is performed through a third-party client — a “black box” where implementation details are hidden and can change at any time, and network or resource configurations are different for each client library and often difficult to monitor and change.
Even worse are transitive dependencies that perform potentially expensive or fault-prone network calls without being explicitly invoked by the application.
Network connections fail or degrade. Services and servers fail or become slow. New libraries or service deployments change behavior or performance characteristics. Client libraries have bugs.
All of these represent failure and latency that needs to be isolated and managed so that a single failing dependency can’t take down an entire application or system.
更严重的是,当网络请求是通过第三方的一个黑盒客户端来发起时,实现细节都被隐藏起来了,而且还可能频繁变动,这样发生问题时就很难监控和改动。如果这个第三方还是通过传递依赖的,主应用程序中根本没有显示地写出调用的代码,那就更难了。网络连接失败或者有延迟,服务将会产生故障或者响应变慢,最终反应成为一个 bug。所有上述表现出来的故障或延迟,都需要一套管理机制,将节点变得相对独立,这样任何一个单节点故障,都至少不会拖垮整个系统的可用性。
What Design Principles Underlie Hystrix?
Hystrix works by:
- Preventing any single dependency from using up all container (such as Tomcat) user threads.
- Shedding load and failing fast instead of queueing.
- Providing fallbacks wherever feasible to protect users from failure.
- Using isolation techniques (such as bulkhead, swimlane, and circuit breaker patterns) to limit the impact of any one dependency.
- Optimizing for time-to-discovery through near real-time metrics, monitoring, and alerting
- Optimizing for time-to-recovery by means of low latency propagation of configuration changes and support for dynamic property changes in most aspects of Hystrix, which allows you to make real-time operational modifications with low latency feedback loops.
- Protecting against failures in the entire dependency client execution, not just in the network traffic.
Hystrix 的设计原则是什么?
Hystrix 通过以下设计原则来运作:
- 防止任何一个单节点将容器中的所有线程都占满
- 通过快速失败,取代放在队列中等待
- 提供在故障时的应急方法(fallback)
- 使用隔离技术 (如 bulkhead, swimlane, 和 circuit breaker patterns) 来限制任何一个依赖项的影响面
- 提供实时监控、报警等手段
- 提供低延迟的配置变更
- 防止客户端执行失败,不仅仅是执行网络请求的客户端
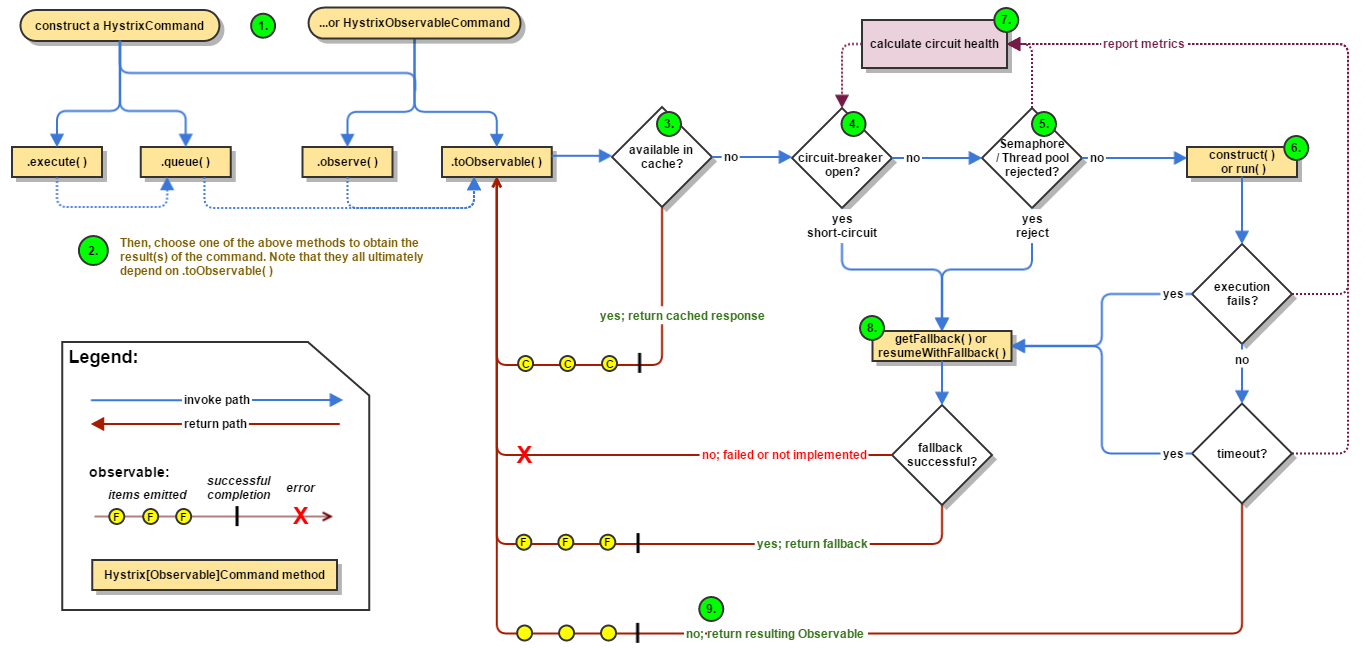
How Does Hystrix Accomplish Its Goals?
Hystrix does this by:
- Wrapping all calls to external systems (or “dependencies”) in a
HystrixCommandorHystrixObservableCommandobject which typically executes within a separate thread (this is an example of the command pattern).- Timing-out calls that take longer than thresholds you define. There is a default, but for most dependencies you custom-set these timeouts by means of “properties” so that they are slightly higher than the measured 99.5th percentile performance for each dependency.
- Maintaining a small thread-pool (or semaphore) for each dependency; if it becomes full, requests destined for that dependency will be immediately rejected instead of queued up.
- Measuring successes, failures (exceptions thrown by client), timeouts, and thread rejections.
- Tripping a circuit-breaker to stop all requests to a particular service for a period of time, either manually or automatically if the error percentage for the service passes a threshold.
- Performing fallback logic when a request fails, is rejected, times-out, or short-circuits.
- Monitoring metrics and configuration changes in near real-time.
When you use Hystrix to wrap each underlying dependency, the architecture as shown in diagrams above changes to resemble the following diagram. Each dependency is isolated from one other, restricted in the resources it can saturate when latency occurs, and covered in fallback logic that decides what response to make when any type of failure occurs in the dependency:
Hystrix 如何时间它的目标?
如下:
- 将远程请求或简单的方法调用包装成
HystrixCommand或者HystrixObservableCommand对象,启动一个单独的线程来运行。- 你可以为服务调用定义一个超时时间,可以为默认值,或者你自定义设置该属性,使得99.5%的请求时间都在该时间以下。
- 为每一个依赖的服务都分配一个线程池,当该线程池满了之后,直接拒绝,这样就防止某一个依赖的服务出问题阻塞了整个系统的其他服务
- 记录成功数、失败数、超时数以及拒绝数等指标
- 设置一个熔断器,将所有请求在一段时间内打到这个熔断器提供的方法上,触发条件可以是手动的,也可以根据失败率自动调整。
- 实时监控配置与属性的变更
当您使用 Hystrix 包装每个基础依赖项时,如上图所示的体系结构将变得类似于下图。每个依赖都是独立的,当延迟发生时,它能够饱和的资源受到限制,并且包含在回退逻辑中,这个逻辑决定依赖中发生任何类型的故障时应该做出什么样的响应:
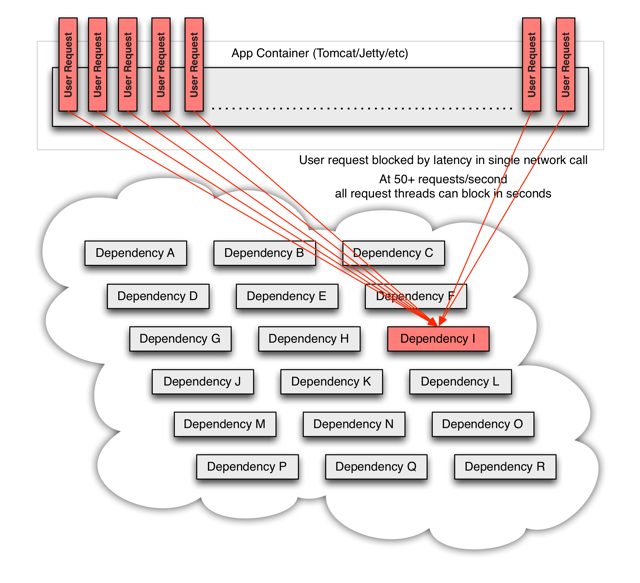
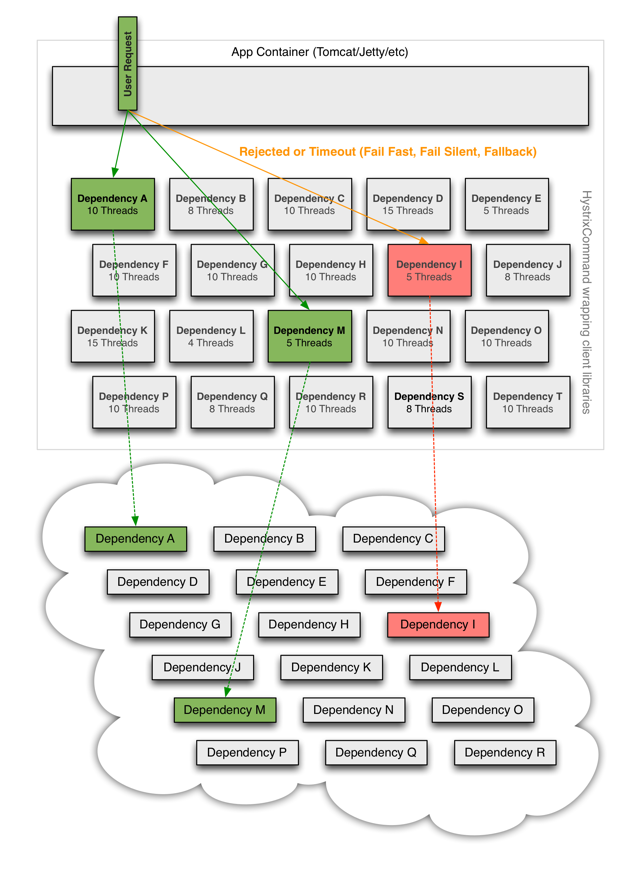
断路器的三个概念:
服务降级
服务降级是当服务器压力剧增的情况下,根据当前业务情况及流量对一些服务和页面有策略的降级,以此释放服务器资源以保证核心任务的正常运行。
要是针对非正常情况下的应急服务措施;比如电商平台,在针对618、双11等高峰情形下采用部分服务不出现或者延时出现的情形。
1 | (1)、延迟服务:比如发表了评论,重要服务,比如在文章中显示正常,但是延迟给用户增加积分,只是放到一个缓存中,等服务平稳之后再执行。 |
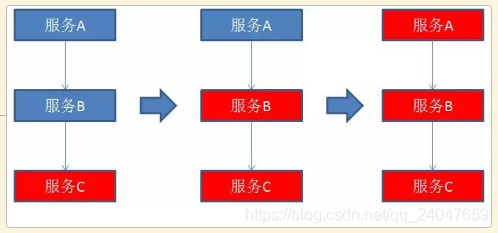
服务熔断
熔断这一概念来源于电子工程中的断路器(Circuit Breaker)。
在互联网系统中,当下游服务因访问压力过大而响应变慢或失败,上游服务为了保护系统整体的可用性,可以暂时切断对下游服务的调用。
这种牺牲局部,保全整体的措施就叫做熔断。
一旦下游服务C因某些原因变得不可用,积压了大量请求,服务B的请求线程也随之阻塞。线程资源逐渐耗尽,使得服务B也变得不可用。紧接着,服务A也变为不可用,整个调用链路被拖垮。
这里需要解释两点:
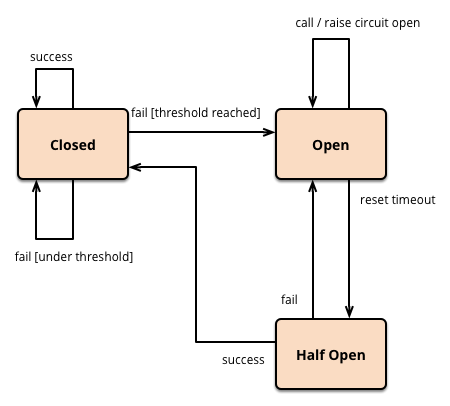
- 开启熔断
在固定时间窗口内,接口调用超时比率达到一个阈值,会开启熔断。
进入熔断状态后,后续对该服务接口的调用不再经过网络,直接执行本地的默认方法,达到服务降级的效果。
熔断恢复
熔断不可能是永久的。
当经过了规定时间之后,服务将从熔断状态回复过来,再次接受调用方的远程调用
服务限流
高并发系统中有三把利器用来保护系统:缓存、降级和限流。限流的目的是为了保护系统不被大量请求冲垮,通过限制请求的速度来保护系统。在电商的秒杀活动中,限流是必不可少的一个环节。限流的方式也有多种,可以在 Nginx 层面限流,也可以在应用当中限流,比如在 API 网关中。
常见的限流算法有:令牌桶、漏桶。计数器也可以进行限流实现。
限流策略:
3.1 服务拒绝
当请求流量达到限流阈值时,对多余的请求直接拒绝。可通过设计实现对指定域名、IP、客户端、应用、用户等不同来源的请求进行拒绝。
3.2 延时处理
通过将多余的请求加入缓存队列或延时队列,来应对短期的流量突增,高峰期过后开始将堆积的请求流量逐渐处理。
3.3 请求分级(优先级)
对不同来源的请求设置优先级,先处理优先级更高的请求。如 VIP 客户、重要的业务应用(如交易服务优先级高于日志服务)
3.4 动态限流
可以监控系统相关指标、评估系统压力,通过注册中心、配置中心等动态调整限流阈值。
3.5 监控预警 &动态扩容
如果有优秀的服务监控系统与自动部署、发布系统,可以通过监控系统自动监测系统运行情况,对短期内服务压力暴增、流量大幅写入的情况进行 邮件、短信等方式进行预警。
限流位置
4.1 接入层限流
可以通过 Nginx、API 路由网关等对域名或 IP 进行限流,同时可以拦截非法请求
4.2 应用限流
每个服务可以有自己的单机或集群限流措施,也可以调用第三方的限流服务
4.3 基础服务限流
数据库:限制数据库连接、限制读写速率
Hystrix 是如何工作的 ?
How it Works · Netflix/Hystrix Wiki (github.com)
https://www.cnblogs.com/cjsblog/p/9395584.html
Gateway
参考教程:Gateway:Spring Cloud API网关组件(非常详细) (biancheng.net)
https://www.cnblogs.com/crazymakercircle/p/11704077.html
官网
在微服务架构中,一个系统往往由多个微服务组成,而这些服务可能部署在不同机房、不同地区、不同域名下。这种情况下,客户端(例如浏览器、手机、软件工具等)想要直接请求这些服务,就需要知道它们具体的地址信息,例如 IP 地址、端口号等。
这种客户端直接请求服务的方式存在以下问题:
- 当服务数量众多时,客户端需要维护大量的服务地址,这对于客户端来说,是非常繁琐复杂的。
- 在某些场景下可能会存在跨域请求的问题。
- 身份认证的难度大,每个微服务需要独立认证。
API 网关
API 网关是一个搭建在客户端和微服务之间的服务,我们可以在 API 网关中处理一些非业务功能的逻辑,例如权限验证、监控、缓存、请求路由等。
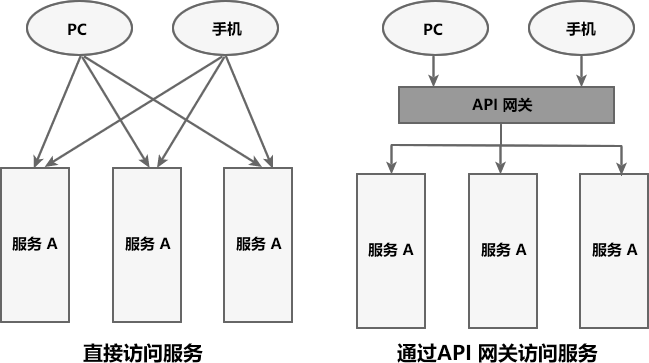
对于服务数量众多、复杂度较高、规模比较大的系统来说,使用 API 网关具有以下好处:
- 客户端通过 API 网关与微服务交互时,客户端只需要知道 API 网关地址即可,而不需要维护大量的服务地址,简化了客户端的开发。
- 客户端直接与 API 网关通信,能够减少客户端与各个服务的交互次数。
- 客户端与后端的服务耦合度降低。
- 节省流量,提高性能,提升用户体验。
- API 网关还提供了安全、流控、过滤、缓存、计费以及监控等 API 管理功能。
常见的 API 网关实现方案主要有以下 5 种:
- Spring Cloud Gateway
- Spring Cloud Netflix Zuul
- Kong
- Nginx+Lua
- Traefik
SpringCloud Zuul的IO模型
Springcloud中所集成的Zuul版本,采用的是Tomcat容器,使用的是传统的Servlet IO处理模型。
大家知道,servlet由servlet container进行生命周期管理。container启动时构造servlet对象并调用servlet init()进行初始化;container关闭时调用servlet destory()销毁servlet;container运行时接受请求,并为每个请求分配一个线程(一般从线程池中获取空闲线程)然后调用service()。
弊端:servlet是一个简单的网络IO模型,当请求进入servlet container时,servlet container就会为其绑定一个线程,在并发不高的场景下这种模型是适用的,但是一旦并发上升,线程数量就会上涨,而线程资源代价是昂贵的(上线文切换,内存消耗大)严重影响请求的处理时间。在一些简单的业务场景下,不希望为每个request分配一个线程,只需要1个或几个线程就能应对极大并发的请求,这种业务场景下servlet模型没有优势。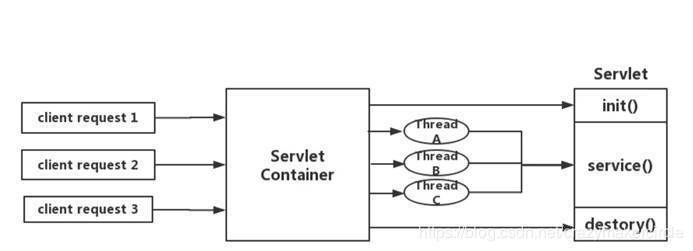
所以Springcloud Zuul 是基于servlet之上的一个阻塞式处理模型,即spring实现了处理所有request请求的一个servlet(DispatcherServlet),并由该servlet阻塞式处理处理。所以Springcloud Zuul无法摆脱servlet模型的弊端。虽然Zuul 2.0开始,使用了Netty,并且已经有了大规模Zuul 2.0集群部署的成熟案例,但是,Springcloud官方已经没有集成改版本的计划了。
Spring Cloud GateWay 概述
Spring Cloud Gateway 是 Spring Cloud 团队基于 Spring 5.0、Spring Boot 2.0 和 Project Reactor 等技术开发的高性能 API 网关组件。
Spring Cloud Gateway 旨在提供一种简单而有效的方式来路由到 API,并为它们提供横切关注点,例如:安全性、监控/指标和弹性
Spring Cloud Gateway 是基于 WebFlux 框架实现的,而 WebFlux 框架底层则使用了高性能的 Reactor 模式通信框架 Netty。它不适用于传统的 Servlet 容器或构建为 WAR 时。


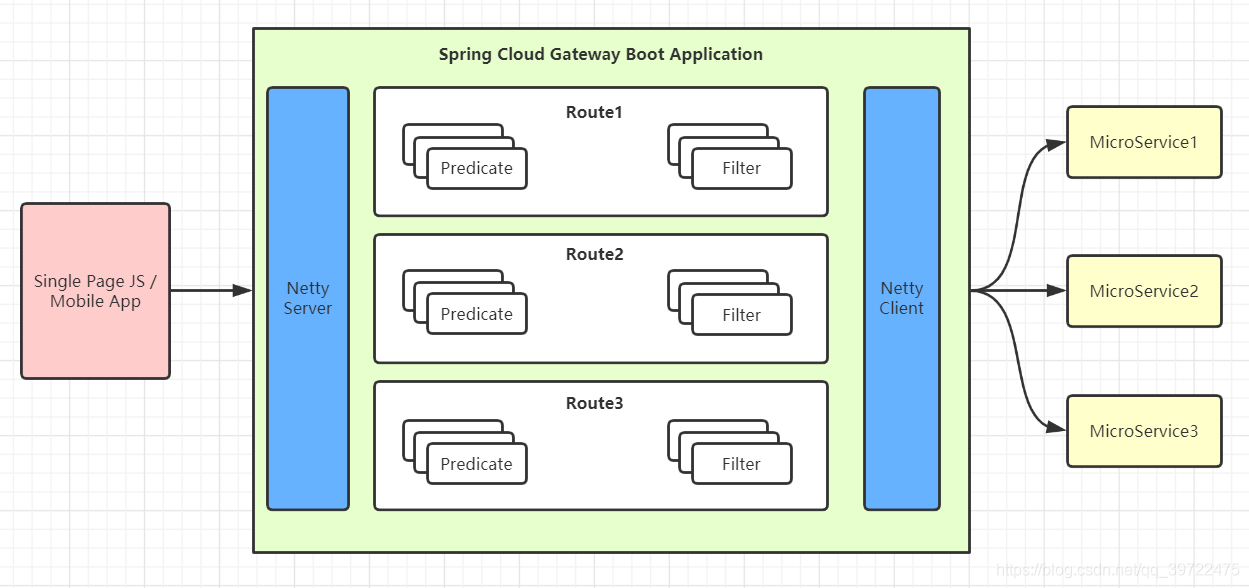
Glossary
- Route: The basic building block of the gateway. It is defined by an ID, a destination URI, a collection of predicates, and a collection of filters. A route is matched if the aggregate predicate is true.
- Predicate: This is a Java 8 Function Predicate. The input type is a Spring Framework
ServerWebExchange. This lets you match on anything from the HTTP request, such as headers or parameters. - Filter: These are instances of Spring Framework
GatewayFilterthat have been constructed with a specific factory. Here, you can modify requests and responses before or after sending the downstream request.
GateWay处理流程
Spring Cloud Gateway 工作流程说明如下:
- 客户端将请求发送到 Spring Cloud Gateway 上。
- Spring Cloud Gateway 通过 Gateway Handler Mapping 找到与请求相匹配的路由,将其发送给 Gateway Web Handler。
- Gateway Web Handler 通过指定的过滤器链(Filter Chain),将请求转发到实际的服务节点中,执行业务逻辑返回响应结果。
- 过滤器之间用虚线分开是因为过滤器可能会在转发请求之前(pre)或之后(post)执行业务逻辑。
- 过滤器(Filter)可以在请求被转发到服务端前,对请求进行拦截和修改,例如参数校验、权限校验、流量监控、日志输出以及协议转换等。
- 过滤器可以在响应返回客户端之前,对响应进行拦截和再处理,例如修改响应内容或响应头、日志输出、流量监控等。
- 响应原路返回给客户端。
总而言之,客户端发送到 Spring Cloud Gateway 的请求需要通过一定的匹配条件,才能定位到真正的服务节点。在将请求转发到服务进行处理的过程前后(pre 和 post),我们还可以对请求和响应进行一些精细化控制。
Predicate 就是路由的匹配条件,而 Filter 就是对请求和响应进行精细化控制的工具。有了这两个元素,再加上目标 URI,就可以实现一个具体的路由了。
SpringCloud Stream
参考:
https://m.wang1314.com/doc/webapp/topic/20971999.html






