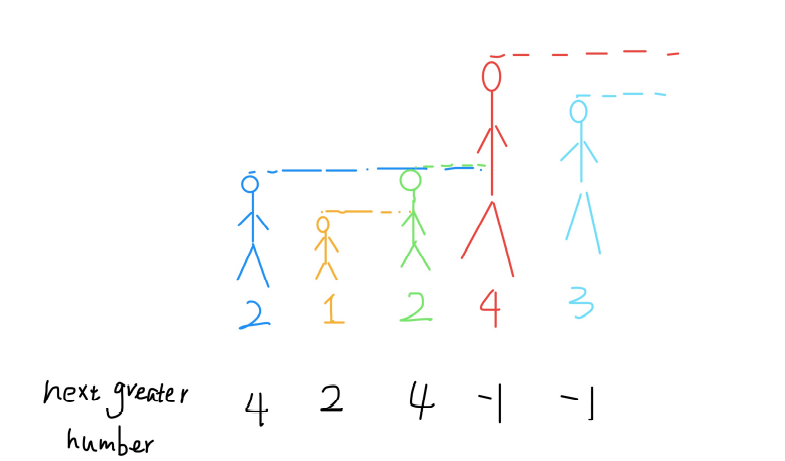
单调栈 Next Greater Number I
给你⼀个数组,返回⼀个等 ⻓的数组,对应索引存储着下⼀个更⼤元素,如果没有更⼤的元素,就存 -1。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution {public : vector<int > nextGreaterElements (vector<int >& nums) { vector<int > res (nums.size()) ; stack<int > stk; for (int i=nums.size ()-1 ;i>=0 ;i--){ while (!stk.empty ()&&stk.top ()<=nums[i]){ s.pop (); } res[i]=stk.empty () ? -1 : stk.top (); stk.push (nums[i]); } return res; } };
这就是单调队列解决问题的模板。for 循环要从后往前扫描元素,因为我们 借助的是栈的结构,倒着⼊栈,其实是正着出栈。while 循环是把两个“⾼ 个”元素之间的元素排除,因为他们的存在没有意义,前⾯挡着个“更⾼”的 元素,所以他们不可能被作为后续进来的元素的 Next Great Number 了。 这个算法的时间复杂度不是那么直观,如果你看到 for 循环嵌套 while 循 环,可能认为这个算法的复杂度也是 O(n^2),但是实际上这个算法的复杂 度只有 O(n)。
Next Greater Number II
给定一个循环数组 nums ( nums[nums.length - 1] 的下一个元素是 nums[0] ),返回 nums 中每个元素的 下一个更大元素 。数字 x 的 下一个更大的元素 是按数组遍历顺序,这个数字之后的第一个比它更大的数,这意味着你应该循环地搜索它的下一个更大的数。如果不存在,则输出 -1 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class Solution { public int [] nextGreaterElements(int [] nums) { int n=nums.length; int [] res= new int [n]; Arrays.fill(res,-1 ); Deque<Integer> stack=new LinkedList <Integer>(); for (int i=n-1 ;i>=0 ;--i){ stack.push(nums[i]); } for (int i=nums.length-1 ;i>=0 ;i--){ while (!stack.isEmpty()&&nums[i] >= stack.peek()) stack.pop(); res[i] = stack.isEmpty()? -1 : stack.peek(); stack.push(nums[i]); } return res; } } vector<int > nextGreaterElements (vector<int >& nums) { int n = nums.size(); vector<int > res (n) ; stack<int > s; for (int i = 2 * n - 1 ; i >= 0 ; i--) { while (!s.empty() && s.top() <= nums[i % n]) s.pop(); res[i % n] = s.empty() ? -1 : s.top(); s.push(nums[i % n]); } return res; }
给你⼀个数组 T = [73, 74, 75, 71, 69, 72, 76, 73],这个数组存放的是近⼏天 的天⽓⽓温(这⽓温是铁板烧?不是的,这⾥⽤的华⽒度)。你返回⼀个数 组,计算:对于每⼀天,你还要⾄少等多少天才能等到⼀个更暖和的⽓温; 如果等不到那⼀天,填 0
Next Greater Number 问题的变体,单调栈中存储的是下标,结果集中存储的是距离
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution { public int [] dailyTemperatures(int [] temperatures) { Deque<Integer> stack =new LinkedList <Integer>(); int n=temperatures.length; int [] res=new int [n]; for (int i=n-1 ;i>=0 ;--i){ while (!stack.isEmpty()&&temperatures[i]>=temperatures[stack.peek()]){ stack.pop(); } res[i]=stack.isEmpty() ? 0 : stack.peek()-i; stack.push(i); } return res; } }
给你一个仅包含小写字母的字符串,请你去除字符串中重复的字母,使得每个字母只出现一次。需保证返回结果的字典序最小(要求不能打乱其他字符的相对位置)。
和上面的题目稍稍有些不同,但如果我们理解了字典序的问题,其实会发现它们也不过就是Next Greater Number 问题,我们的困惑可能是本题中当我们遇到重复元素时,我们应该删除哪一个
思路:
遍历字符串:
如果该元素当前已经出现在栈中,直接舍弃,因为不会在构成更小的字典序
如果当前元素严格大于栈顶元素,且还会在之后的遍历中再次出现,那么一定可以构成更小的字典序,可以直接舍弃
没有出现上述两种情况,则该元素不在栈中,且要么能够构成更小的字典序,要么该字符在串中唯一,符合入栈的条件
关键:维护一个分段单调的栈
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class Solution { public String removeDuplicateLetters (String s) { int len=s.length(); boolean [] vis = new boolean [26 ]; char [] charArray=s.toCharArray(); int [] lastIndex = new int [26 ]; Deque<Character> stk =new ArrayDeque <>(); for (int i=0 ;i<len;++i){ lastIndex[charArray[i]-'a' ]=i; } for (int i=0 ;i<len;++i){ char cur=charArray[i]; int index=cur-'a' ; if (vis[index]) continue ; while (!stk.isEmpty()&&stk.peek()>cur&&lastIndex[stk.peek()-'a' ]>i){ char top=stk.pop(); vis[top-'a' ]=false ; } stk.push(cur); vis[index]=true ; } StringBuilder builder=new StringBuilder (); for (char c:stk){ builder.append(c); } builder.reverse(); return builder.toString(); } }
给定一个整数数组,它表示BST(即 二叉搜索树 )的 先序遍历 ,构造树并返回其根。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 class Solution { public TreeNode bstFromPreorder (int [] preorder) { return helper(preorder,0 ,preorder.length-1 ); } TreeNode helper (int [] preorder,int left,int right) { if (right-left<0 )return null ; TreeNode root = new TreeNode (preorder[left]); int index=-1 ; for (int i=left+1 ;i<=right;++i){ if (preorder[i]>preorder[left]){ index=i; break ; } } if (index!=-1 ){ root.left = helper(preorder,left+1 ,index-1 ); root.right= helper(preorder,index ,right); } else { root.left=helper(preorder,left+1 ,right); } return root; } } public class Solution { public TreeNode bstFromPreorder (int [] preorder) { int len = preorder.length; if (len == 0 ) { return null ; } TreeNode root = new TreeNode (preorder[0 ]); Deque<TreeNode> stack = new ArrayDeque <>(); stack.push(root); for (int i = 1 ; i < len; i++) { TreeNode node = stack.peekLast(); TreeNode currentNode = new TreeNode (preorder[i]); while (!stack.isEmpty() && stack.peekLast().val < currentNode.val) { node = stack.removeLast(); } if (node.val < currentNode.val) { node.right = currentNode; } else { node.left = currentNode; } stack.addLast(currentNode); } return root; } }
用栈模拟递归遍历二叉树 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 class Solution { public List<Integer> preorderTraversal (TreeNode root) { List<Integer> res=new ArrayList <>(); if (root==null ) return res; Deque<TreeNode> stack=new ArrayDeque <>(); stack.push(root); while (!stack.isEmpty()){ TreeNode node=stack.pop(); res.add(node.val); if (node.right!=null ){ stack.push(node.right); } if (node.left!=null ){ stack.push(node.left); } } return res; } public List<Integer> inorderTraversal (TreeNode root) { List<Integer> res=new ArrayList <>(); if (root=null ) return res; Deque<TreeNode> stack=new ArrayDeque <>(); stack.push(root); while (cur!=null ||!stack.isEmpty()){ if (cur!=null ){ stack.push(cur); cur=cur.left; } else { cur=stack.pop(); res.add(cur.val); cur=cur.right; } } } public List<Integer> postorderTraversal (TreeNode root) { List<Integer> res=new ArrayList <>(); if (root=null ) return res; Deque<TreeNode> stack= new ArrayDeque <>(); stack.push(root); while (!stack.isEmpty()){ TreeNode node = stack.pop(); res.add(node.val); if (node.left!=null ){ stack.push(node.left); } if (node.right!=null ){ stack.push(node.right); } } Colletions.reverse(res); return res; } }
单调队列
给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。
分析:
这道题不复杂,难点在于如何在 O(1) 时间算出每个「窗⼝」中的最⼤值, 使得整个算法在线性时间完成。在之前我们探讨过类似的场景,得到⼀个结 论: 在⼀堆数字中,已知最值,如果给这堆数添加⼀个数,那么⽐较⼀下就可以 很快算出最值;但如果减少⼀个数,就不⼀定能很快得到最值了,⽽要遍历 所有数重新找最值。 回到这道题的场景,每个窗⼝前进的时候,要添加⼀个数同时减少⼀个数, 所以想在 O(1) 的时间得出新的最值,就需要「单调队列」这种特殊的数据 结构来辅助了。
此题的关键点:已知一个窗口数组内的最值,此时要同时在窗口右侧添加一个数,且在窗口左侧删除一个数,并更新最值。当我们使用单调队列时,push一个数,根据单调队列的性质我们知道队首元素即为窗口最大值,pop一个数时,如果这个数等于最值,此时窗口最大值更新。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 class MonotonicQueue { private ArrayDeque<Integer> deque; public MonotonicQueue () { deque=new ArrayDeque <>(); } public void push (int n) { while (!deque.isEmpty()&&deque.getLast()<n){ deque.removeLast(); } deque.addLast(n); } public int max () { return deque.getFirst(); } public void pop (int n) { if (!deque.isEmpty()&&deque.getFirst()==n){ deque.removeFirst(); } } } class Solution { public int [] maxSlidingWindow(int [] nums, int k) { int [] res=new int [nums.length-k+1 ]; int count=0 ; MonotonicQueue windom=new MonotonicQueue (); for (int i=0 ;i<nums.length;++i){ if (i<k-1 ){ windom.push(nums[i]); } else { windom.push(nums[i]); res[count]=windom.max(); windom.pop(nums[i-k+1 ]); count++; } } return res; } }
堆 堆的性质:
完全二叉树 ,定义:一棵深度为k的有n个结点的二叉树 ,对树中的结点按从上至下、从左到右的顺序进行编号,如果编号为i(1≤i≤n)的结点与满二叉树 中编号为i的结点在二叉树中的位置相同,则这棵二叉树称为完全二叉树。
父节点值 > 子节点值(大根堆)
堆排序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 class Heap_sort { private void swap (int [] tree,int i,int j) { int tmp; tmp=tree[i]; tree[i]=tree[j]; tree[j]=tmp; } private static void buildMaxHeap (int [] tree,int n) { int last_node=n-1 ; int last_node_parent=(last_node-1 )/2 ; for (int i=last_node_parent;i>=0 ;i--){ heapify(tree,n,i); } } private void heapify (int [] tree,int n,int i) { if (i>=n) return ; int c1=2 *i+1 ; int c2=2 *i+2 ; int max=i; if (c1<n&&tree[c1]>tree[max]){ max=c1; } if (c2<n&&tree[c2]>tree[max]){ max=c2; } if (max!=i){ swap(tree,max,i); heapify(tree,n,max); } } public static void heap_sort (int [] tree,int n) { buildMaxHeap(tree,n); int i; for (int i=n-1 ;i>=0 ;i--){ swap(tree,i,0 ); heapify(tree,i,0 ); } } }
给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。
首先遍历整个数组,并使用哈希表记录每个数字出现的次数,并形成一个「出现次数数组」。找出原数组的前 k个高频元素,就相当于找出「出现次数数组」的前 kk 大的值。
最简单的做法是给「出现次数数组」排序。但由于可能有 O(N)个不同的出现次数(其中 N 为原数组长度),故总的算法复杂度会达到 O(N\log N),不满足题目的要求。
在这里,我们可以利用堆的思想:建立一个小顶堆,然后遍历「出现次数数组」:
如果堆的元素个数小于 k,就可以直接插入堆中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution { public int [] topKFrequent(int [] nums, int k) { int [] res=new int [k]; HashMap<Integer,Integer> map=new HashMap <>(); for (int num:nums){ map.put(num,map.getOrDefault(num,0 )+1 ); } Set<Map.Entry<Integer,Integer>> entrys=map.entrySet(); PriorityQueue<Map.Entry<Integer,Integer>> queue=new PriorityQueue <>((o1,o2)->o1.getValue()-o2.getValue()); for ( Map.Entry<Integer,Integer> entry : entrys){ if (queue.size()<k) queue.offer(entry); else { if (entry.getValue()>queue.peek().getValue()){ queue.poll(); queue.offer(entry); } } } for (int i=0 ;i<k;++i){ res[i]=queue.poll().getKey(); } return res; } }
时间复杂度:O(Nlogk),其中 N为数组的长度。我们首先遍历原数组,并使用哈希表记录出现次数,每个元素需要 O(1) 的时间,共需 O(N) 的时间。随后,我们遍历「出现次数数组」,由于堆的大小至多为 k,因此每次堆操作需要 O(logk) 的时间,共需 O(Nlogk) 的时间。二者之和为O(Nlogk)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 class Solution { public int nthUglyNumberByHeap (int n) { HashSet<Long> seen=new HashSet <>(); PriorityQueue<Long> heap=new PriorityQueue <>(); long num=1 ; heap.add(1L ); int [] factors={2 ,3 ,5 }; for (int k=1 ;k<=n;k++){ num=heap.poll(); for (int i=0 ;i<factors.length;++i){ long temp=factors[i]*num; if (seen.add(temp)){ heap.add(temp); } } } return (int )num; } private int Min (int a,int b) { return a<b?a:b; } public int nthUglyNumberByThreePointer (int n) { int [] dp=new int [n]; int p2=0 ,p3=0 ,p5=0 ; dp[0 ]=1 ; for (int i=1 ;i<n;++i){ int a=dp[p2]*2 ,b=dp[p3]*3 ,c=dp[p5]*5 ; int min=Min(a,Min(b,c)); dp[i]=min; if (a==min) p2++; if (b==min) p3++; if (c==min) p5++; } return dp[n-1 ]; } public int nthUglyNumber (int n) { return nthUglyNumberByThreePointer(n); } }
双指针
滑动窗口 (90%)
时间复杂度要求 O(n) (80%是双指针)
要求原地操作,只可以使用交换,不能使用额外空间 (80%)
有子数组 subarray / 子字符串 substring 的关键词 (50%)
有回文 Palindrome
判定链表中是否含有环 经典解法就是⽤两个指针,⼀个跑得快,⼀个跑得慢。如果不含有环,跑得 快的那个指针最终会遇到 null,说明链表不含环;如果含有环,快指针最终 会超慢指针⼀圈,和慢指针相遇,说明链表含有环。
1 2 3 4 5 6 7 8 ListNode fast, slow; fast = slow = head; while (fast != null && fast.next != null ) { fast = fast.next.next; slow = slow.next; if (fast == slow) return true ; } return false
已知链表中含有环,返回这个环的起始位置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ListNode detectCycle (ListNode head) { ListNode fast, slow; fast = slow = head; while (fast != null && fast.next != null ) { fast = fast.next.next; slow = slow.next; if (fast == slow) break ; } if (fast==null ||fast.next==null ) return null ;slow = head; while (slow != fast) { fast = fast.next; slow = slow.next; } return slow;}
有序数组的 Two Sum
你一个下标从 1 开始的整数数组 numbers ,该数组已按 非递减顺序排列 ,请你从数组中找出满足相加之和等于目标数 target 的两个数。如果设这两个数分别是 numbers[index1] 和 numbers[index2] ,则 1 <= index1 < index2 <= numbers.length 。
对于 两数之和 I 的题,我们使用 遍历+哈希表 来降低时间复杂度,对于本题,要求是常数空间,且数组按 非递减顺序排列 ,一个好的方法是使用双指针,使得时间复杂度为O(n),空间复杂度为O(1)
使用双指针,一个指针指向值较小的元素,一个指针指向值较大的元素。指向较小元素的指针从头向尾遍历,指向较大元素的指针从尾向头遍历。
如果两个指针指向元素的和 sum == target,那么得到要求的结果;
如果 sum > target,移动较大的元素,使 sum 变小一些;
如果 sum < target,移动较小的元素,使 sum 变大一些。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Solution { public int [] twoSum(int [] numbers, int target) { if (numbers.length<2 ) return null ; int i=0 ;int j=numbers.length-1 ; int [] res=new int [2 ]; int sum=0 ; while (i<j){ sum=numbers[i]+numbers[j]; if (sum==target) { res[0 ]=i+1 ; res[1 ]=j+1 ; break ; } else if (sum<target){ i++; }else { j--; } } return res; } }
给定一个非负整数 c ,你要判断是否存在两个整数 a 和 b,使得 a2 + b2 = c 。
和上一个题本质上是一样的。关键在于为什么用双指针一定不会错过正确答案:为什么双指针不会错过正确答案
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution { public boolean judgeSquareSum (int c) { long i=0 ; long sum=0 ; long j = (int ) Math.sqrt(c)+2 ; while (i<=j){ sum=i*i+j*j; if (sum==c){ return true ; } else if (sum<c){ i++; } else { j--; } } return false ; } }
给你一个字符串 s ,仅反转字符串中的所有元音字母,并返回结果字符串。元音字母包括 'a'、'e'、'i'、'o'、'u',且可能以大小写两种形式出现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution { public String reverseVowels (String s) { int n=s.length(); char [] arr=s.toCharArray(); int i=0 , j = n-1 ; while (i<j){ while (i<n-1 &&!isVowel(arr[i])){ ++i; } while (j >=0 &&!isVowel(arr[j])){ --j; } if (i < j){ swap(arr,i,j); ++i; --j; } } return new String (arr); } public boolean isVowel (char ch) { return "aeiouAEIOU" .indexOf(ch)>=0 ; } public void swap (char [] arr,int i,int j) { char temp=arr[i]; arr[i]=arr[j]; arr[j]=temp; } }
回文字符串
给定一个非空字符串 s,最多 删除一个字符。判断是否能成为回文字符串。
双指针,i ->, <-j , 若遇到不匹配的时候,则让两个指针分别向各自的方向移动,若再不匹配,则不符合要求
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Solution { public boolean validPalindrome (String s) { int n=s.length(); if (n<=2 ) return true ; char [] arr=s.toCharArray(); int i=0 ,j=n-1 ; while (i<j){ if (arr[i]==arr[j]){ i++; j--; } else return helper(arr,i+1 ,j) | helper(arr,i,j-1 ); } return true ; } public boolean helper (char [] arr,int i,int j) { while (i<j){ if (arr[i]==arr[j]){ i++; j--; } else return false ; } return true ; } }
给你一个字符串 s 和一个字符串数组 dictionary ,找出并返回 dictionary 中最长的字符串,该字符串可以通过删除 s 中的某些字符得到。如果答案不止一个,返回长度最长且字母序最小的字符串。如果答案不存在,则返回空字符串。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 class Solution { public String findLongestWord (String s, List<String> dictionary) { String res="" ; int len=dictionary.size(); for (int i=0 ;i<len;++i){ String t=dictionary.get(i); if (isValidate(s,t)){ if (res!=null ){ if (res.length()!=t.length()){ res = res.length()>t.length()?res:t; } else { int n=t.length(); for (int j=0 ;j<n;++j){ if (t.charAt(j)<res.charAt(j)) { res=t; break ; } else if (t.charAt(j)>res.charAt(j)) { break ; } } } } else res=t; } } return res; } public boolean isValidate (String pattern,String s) { int j=0 ; for (int i=0 ;i<pattern.length();i++){ if (pattern.charAt(i)==s.charAt(j)) ++j; if (j==s.length()) return true ; } return false ; } }
给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?请你找出所有和为 0 且不重复的三元组。注意:答案中不可以包含重复的三元组。
先将nums排序,再不重复的枚举nums中的元素,我们的目标是三个数的和为0,此时只需要在数组中找到两个数之和为枚举的元素的相反数即可,此时问题就能转化为有序数组的 Two Sum 问题,而关键在于要进行去重
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution { public List<List<Integer>> threeSum (int [] nums) { List<List<Integer>> res=new ArrayList <>(); Arrays.sort(nums); int n=nums.length;int tar; for (int i=0 ;i<n;++i){ if (i>0 &&nums[i]==nums[i-1 ]) continue ; int q=n-1 ; tar=-nums[i]; for (int p=i+1 ;p<n;++p){ if (p>i+1 &&nums[p]==nums[p-1 ]) continue ; while (p<q&&nums[p]+nums[q]>tar) --q; if (q==p) break ; if (nums[p]+nums[q]==tar){ List<Integer> r=new ArrayList <>(); r.add(nums[i]); r.add(nums[p]); r.add(nums[q]); res.add(r); } } } return res; } }
四数之和
给你一个由 n 个整数组成的数组 nums ,和一个目标值 target 。请你找出并返回满足下述全部条件且不重复的四元组 [nums[a], nums[b], nums[c], nums[d]] (若两个四元组元素一一对应,则认为两个四元组重复):
0 <= a, b, c, d < n
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class Solution { public List<List<Integer>> fourSum (int [] nums, int target) { List<List<Integer>> res=new ArrayList <>(); Arrays.sort(nums); int n=nums.length;int tar; for (int j=0 ;j<n;++j){ if (j>0 &&nums[j]==nums[j-1 ]) continue ; for (int i=j+1 ;i<n;++i){ if (i>j+1 &&nums[i]==nums[i-1 ]) continue ; int q=n-1 ; tar=target-(nums[j]+nums[i]); for (int p=i+1 ;p<n;++p){ if (p>i+1 &&nums[p]==nums[p-1 ]) continue ; while (p<q&&nums[p]+nums[q]>tar) --q; if (q==p) break ; if (nums[p]+nums[q]==tar){ List<Integer> r=new ArrayList <>(); r.add(nums[j]); r.add(nums[i]); r.add(nums[p]); r.add(nums[q]); res.add(r); } } } } return res; } }
给你一个数组 nums 和一个值 val,你需要 原地 val 的元素,并返回移除后数组的新长度。
题目比较具有迷惑性,其实需要做的就是将要输出的元素提前即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Solution { public int removeElement (int [] nums, int val) { int k=0 ; for (int i=0 ;i<nums.length;++i){ if (nums[i]!=val) { nums[k]=nums[i]; k++; } } return k; } }
给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的新数组,要求也按 非递减顺序 排序。
数组其实是有序的, 只不过负数平方之后可能成为最大数了。那么数组平方的最大值就在数组的两端,不是最左边就是最右边,不可能是中间。此时可以考虑双指针法了,i指向起始位置,j指向终止位置。定义一个新数组result,和A数组一样的大小,让k指向result数组终止位置,从大到小将数组填满
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution { public int [] sortedSquares(int [] nums) { int len = nums.length; int [] res=new int [len]; int head=0 ,tail=len-1 ; for (int i=len-1 ;i>=0 ;--i){ if (nums[tail]*nums[tail]>nums[head]*nums[head]){ res[i]=nums[tail]*nums[tail]; tail--; } else { res[i]=nums[head]*nums[head]; head++; } } return res; } }
给定一个含有 n 个正整数的数组和一个正整数 target 。找出该数组中满足其和 ≥ target 的长度最小的 连续子数组 [numsl, numsl+1, …, numsr-1, numsr] ,并返回其长度。如果不存在符合条件的子数组,返回 0 。
这道题目暴力解法当然是 两个for循环,然后不断的寻找符合条件的子序列,时间复杂度很明显是O(n^2)。我们可以将暴力解法作为一种启发式的算法。
暴力解法之所以复杂度高,就在于它做了许多的重复计算,每一次sum都要重新归零 ,这个题我们可以利用滑动窗口的方法,不需要将sum每次都归零,而是将它减小至刚好小于sum的程度,然后再加后面的元素,更新窗口的大小。这样就能够降低复杂度。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution { public int minSubArrayLen (int target, int [] nums) { int res=Integer.MAX_VALUE; int sum=0 ; int i=0 ; int len=nums.length; for (int j=0 ;j<len;++j){ sum+=nums[j]; while (sum>=target){ res= Math.min(res,j-i+1 ); sum-=nums[i++]; } } return res==Integer.MAX_VALUE?0 :res; } }
二分搜索
整数数组 nums 按升序排列,数组中的值 互不相同 。在传递给函数之前,nums 在预先未知的某个下标 k(0 <= k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k+1], …, nums[n-1], nums[0], nums[1], …, nums[k-1]](下标 从 0 开始 计数)。例如, [0,1,2,4,5,6,7] 在下标 3 处经旋转后可能变为 [4,5,6,7,0,1,2] 。给你 旋转后 的数组 nums 和一个整数 target ,如果 nums 中存在这个目标值 target ,则返回它的下标,否则返回 -1 。
分段递增的数组,我们可以将其分成两段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 class Solution { public int search (int [] nums, int target) { int mid=nums.length-1 ; int res=-1 ; int end=nums[nums.length-1 ]; if (mid==0 ) { if (nums[mid]==target) return mid; else return -1 ; } while (mid>=1 &&nums[mid-1 ]<end){ mid--; } if (mid>=1 ){ res=BinarySearch(nums,0 ,mid-1 ,target); if (res!=-1 ) return res; res=BinarySearch(nums,mid,nums.length-1 ,target); }else { res=BinarySearch(nums,0 ,nums.length-1 ,target); } return res; } private static int BinarySearch (int [] nums,int start ,int end, int target) { int mid; int l=start,r=end; while (l<=r){ mid=(l+r) / 2 ; if (nums[mid]>target){ r=mid-1 ; } else if (nums[mid]<target){ l=mid+1 ; } else return mid; } return -1 ; } }
给定一个按照升序排列的整数数组 nums,和一个目标值 target。找出给定目标值在数组中的开始位置和结束位置。如果数组中不存在目标值 target,返回 [-1, -1]。
排序数组是非降序的,但我们用二分搜索找到目标元素时,就可以将指针向两侧移动,移动到目标元素的开始位置和结束位置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 class Solution { public int [] searchRange(int [] nums, int target) { int l=0 ,r=nums.length-1 ;int [] res={-1 ,-1 }; int mid=-1 ; while (l<=r){ mid=l+((r-l)>>1 ); if (nums[mid]<target){ l=mid+1 ; } else if (nums[mid]>target){ r=mid-1 ; } else { l=r=mid; while (r<nums.length-1 &&nums[r+1 ]==nums[r]) r++; while (l>0 &&nums[l-1 ]==nums[l]) l--; res[0 ]=l; res[1 ]=r; return res; } } return res; } } class Solution { int [] searchRange(int [] nums, int target) { int leftBorder = getLeftBorder(nums, target); int rightBorder = getRightBorder(nums, target); if (leftBorder == -2 || rightBorder == -2 ) return new int []{-1 , -1 }; if (rightBorder - leftBorder > 1 ) return new int []{leftBorder + 1 , rightBorder - 1 }; return new int []{-1 , -1 }; } int getRightBorder (int [] nums, int target) { int left = 0 ; int right = nums.length - 1 ; int rightBorder = -2 ; while (left <= right) { int middle = left + ((right - left) / 2 ); if (nums[middle] > target) { right = middle - 1 ; } else { left = middle + 1 ; rightBorder = left; } } return rightBorder; } int getLeftBorder (int [] nums, int target) { int left = 0 ; int right = nums.length - 1 ; int leftBorder = -2 ; while (left <= right) { int middle = left + ((right - left) / 2 ); if (nums[middle] >= target) { right = middle - 1 ; leftBorder = right; } else { left = middle + 1 ; } } return leftBorder; } }
1 2 3 输入:nums = [4,5,6,7,0,1,2] 输出:0 解释:原数组为 [0,1,2,4,5,6,7]
这类似于两个上升的陡坡,中间元素必定在其中一个坡上,我们要求的是第二个坡上的第一个元素,判断条件为:nums[mid]<nums[r]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution { public int findMin (int [] nums) { int l=0 ,r=nums.length-1 ; int mid; while (l<r){ mid=l+((r-l)>>1 ); if (nums[mid] < nums[r]){ r=mid; } else { l=mid+1 ; } } return nums[l]; } }
链表 重要方法:双指针
移除链表节点
删除链表中等于给定值 val 的所有节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 public ListNode removeElements (ListNode head, int val) { if (head == null ) { return head; } ListNode dummy = new ListNode (-1 , head); ListNode pre = dummy; ListNode cur = head; while (cur != null ) { if (cur.val == val) { pre.next = cur.next; } else { pre = cur; } cur = cur.next; } return dummy.next; } public ListNode removeElements (ListNode head, int val) { while (head != null && head.val == val) { head = head.next; } if (head == null ) { return head; } ListNode pre = head; ListNode cur = head.next; while (cur != null ) { if (cur.val == val) { pre.next = cur.next; } else { pre = cur; } cur = cur.next; } return head; }
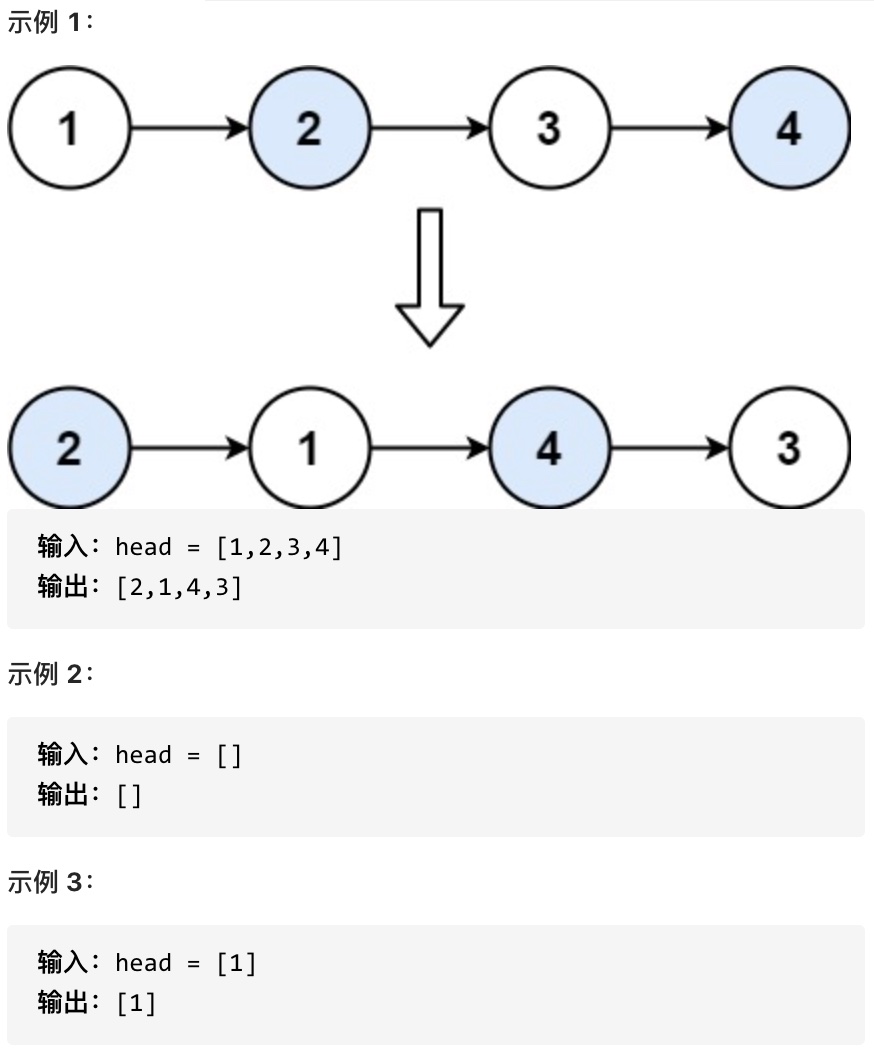
设计链表 两两交换链表中的节点
给定一个链表,两两交换其中相邻的节点,并返回交换后的链表。你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution { public ListNode swapPairs (ListNode head) { ListNode dummy = new ListNode (0 ); dummy.next=head; ListNode prev = dummy; while (prev.next!=null &&prev.next.next!=null ){ ListNode temp=prev.next.next; prev.next.next=temp.next; temp.next = prev.next; prev.next=temp; prev=prev.next.next; } return dummy.next; } }
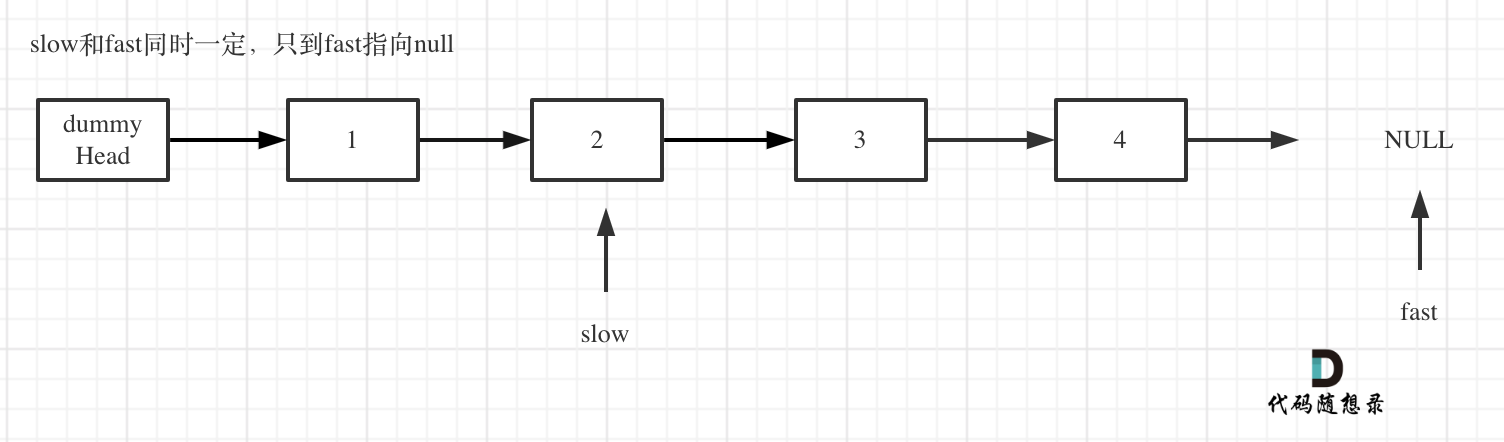
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
目的是找到一个倒数第n个结点,然后删除之。我们可以利用双指针,一次扫描即可找到倒数第n个结点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution { public ListNode removeNthFromEnd (ListNode head, int n) { ListNode dummy=new ListNode (0 ); dummy.next=head; ListNode slow=dummy,fast=dummy; int count=0 ; while (fast!=null &&count!=n+1 ){ fast=fast.next; count++; } while (fast!=null ){ fast=fast.next; slow=slow.next; } slow.next=slow.next.next; return dummy.next; } }
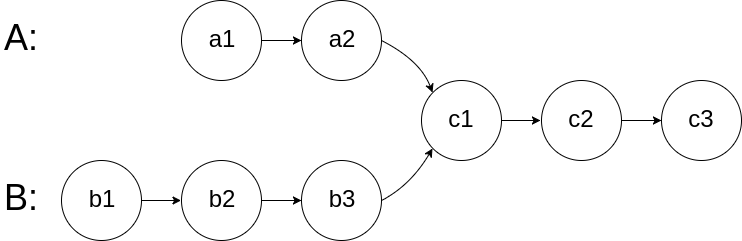
链表相交
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表没有交点,返回 null 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 public class Solution { public ListNode getIntersectionNode (ListNode headA, ListNode headB) { if (headA==null |headB==null )return null ; ListNode curA = headA; ListNode curB = headB; int lenA = 0 , lenB = 0 ; while (curA!=null ){ curA=curA.next; lenA++; } while (curB!=null ){ curB=curB.next; lenB++; } curA=headA; curB=headB; if (lenA>=lenB){ int dif=lenA-lenB; while (dif!=0 ) { curA=curA.next; dif--; } } else { int dif=lenB-lenA; while (dif!=0 ) { curB=curB.next; dif--; } } while (curA!=null &&curB!=curA){ curA=curA.next; curB=curB.next; } return curA; } }
翻转链表
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution { public ListNode reverseList (ListNode head) { ListNode pre=null ,cur=head; while (cur!=null ){ ListNode temp=cur.next; cur.next=pre; pre=cur; cur=temp; } return p; } } class Solution { public ListNode reverseList (ListNode head) { if (head.next==null ) return head; ListNode last = reverseList(head.next); head.next.next=head; head.next=null ; return last; } }
哈希表 有效的字母异位词
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
注意:若 s 和 t 中每个字符出现的次数都相同,则称 s 和 t 互为字母异位词
求取字符出现的次数是否相同,应该立刻想到使用hash表法,关于字母的hash表,我们可以使用数组来实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution { public boolean isAnagram (String s, String t) { int [] record = new int [26 ]; for (char c:s.toCharArray()){ record[c-'a' ]+=1 ; } for (char c :t.toCharArray()){ record[c-'a' ]-=1 ; } for (int i : record){ if (i!=0 ) return false ; } return true ; } }
给定两个数组 nums1 和 nums2 ,返回 它们的交集 。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序
求两个数组的交集,我们可以利用hash表来求取,将其中一个数组的元素放在set1中,遍历另一个数组的元素,如果set1中包含了这个元素,则将它放到set2中(为了去重),最后返回返回set2中的元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution { public int [] intersection(int [] nums1, int [] nums2) { HashSet<Integer> set = new HashSet <>(); HashSet<Integer> resset = new HashSet <>(); for (int i : nums1){ set.add(i); } for (int i : nums2){ if (set.contains(i)) resset.add(i); } Iterator<Integer> iterator = resset.iterator(); int size=resset.size(); int [] res=new int [size]; size=0 ; while (iterator.hasNext()){ res[size]=iterator.next(); size++; } return res; } }
「快乐数」 定义为:
对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。
然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。
如果这个过程 结果为 1,那么这个数就是快乐数。
如果 n 是 快乐数 就返回 true ;不是,则返回 false
题目中说了会 无限循环 ,那么也就是说求和的过程中,sum会重复出现,这对解题很重要!
当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution { public boolean isHappy (int n) { HashSet<Integer> set = new HashSet <>(); while (!set.contains(n)){ set.add(n); n=getSum(n); if (n==1 ) return true ; } return false ; } private int getSum (int n) { int sum=0 ; while (n>0 ){ sum+=(n%10 )*(n%10 ); n /= 10 ; } return sum; } }
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
1 2 3 4 5 6 7 8 9 10 11 class Solution { public int [] twoSum(int [] nums, int target) { HashMap<Integer,Integer> map = new HashMap <>(); for (int i=0 ;i<nums.length;++i){ Integer n=map.get(target-nums[i]); if (n!=null ) return new int []{n,i}; else map.put(nums[i],i); } return null ; } }
给你四个整数数组 nums1、nums2、nums3 和 nums4 ,数组长度都是 n ,请你计算有多少个元组 (i, j, k, l) 能满足:
0 <= i, j, k, l < n
nums1[i] + nums2[j] + nums3[k] + nums4[l] == 0
将问题转化为无需去重的两数之和的问题,将四个数组分成两组,一组求和,并连同其出现的次数存入HashMap中,另一组求和计算相反数,并在哈希表中查找。 这样就将问题转化为无需去重的两数之和
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution { public int fourSumCount (int [] nums1, int [] nums2, int [] nums3, int [] nums4) { HashMap<Integer,Integer> map=new HashMap <>(); int temp=0 ,res=0 ; for (int a: nums1){ for (int b: nums2){ temp=a+b; map.put(temp,map.getOrDefault(temp,0 )+1 ); } } for (int c:nums3){ for (int d: nums4){ temp=c+d; if (map.containsKey(0 -temp)){ res+=map.get(0 -temp); } } } return res; } }
赎金信
给你两个字符串:ransomNote 和 magazine ,判断 ransomNote 能不能由 magazine 里面的字符构成。
和字母异位词类似,唯一不同的是本题中一个字符串中的字母数量种类是另一个字符串的子集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution { public boolean canConstruct (String ransomNote, String magazine) { int [] record=new int [26 ]; int len=magazine.length(); int index=-1 ; for (int i=0 ;i<len;++i){ index=magazine.charAt(i)-'a' ; record[index]+=1 ; } len=ransomNote.length(); for (int i=0 ;i<len;++i){ index=ransomNote.charAt(i)-'a' ; if (record[index]>0 ) record[index]--; else return false ; } return true ; } }
有效的数独
请你判断一个 9 x 9 的数独是否有效。只需要 根据以下规则 ,验证已经填入的数字是否有效即可。
数字 1-9 在每一行只能出现一次。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution { public boolean isValidSudoku (char [][] board) { int [][] rows = new int [9 ][9 ]; int [][] columns = new int [9 ][9 ]; int [][][] subboxes = new int [3 ][3 ][9 ]; for (int i=0 ;i<9 ;++i){ for (int j=0 ;j<9 ;++j){ if (board[i][j]=='.' ) continue ; int num=board[i][j]-'0' -1 ; rows[i][num]++; columns[j][num]++; subboxes[i/3 ][j/3 ][num]++; if (rows[i][num]>1 ||columns[j][num]>1 ||subboxes[i/3 ][j/3 ][num]>1 ) return false ; } } return true ; } }
字符串 参考: https://blog.csdn.net/qq_21808961/article/details/80504104
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 public boolean equals (Object anObject) 判断字符串内容是否相等的方法public boolean equalsIgnoreCase (String anotherString) 忽略大小写判断字符串内容是否相同的方法public boolean contains (CharSequence s) 当且仅当此字符串包含指定的 char 值序列时,返回 true 。public boolean equalsIgnoreCase (String anotherString) 将此 String 与另一个 String 比较,不考虑大小写。public boolean matches (String regex) 告知此字符串是否匹配给定的正则表达式。 boolean startsWith (String prefix) 测试此字符串是否以指定的前缀开始。 boolean startsWith (String prefix, int toffset) 测试此字符串从指定索引开始的子字符串是否以指定前缀开始。boolean endsWith (String suffix) 测试此字符串是否以指定的后缀结束。 public int length () 返回字符串长度public String concat (String string) 将指定字符串连接到该字符串末尾public char charat (int index) 返回指定索引处的char 值public int indexOf (String str) 返回指定字符串第一次出现的地方public String substring (int beginIndex) 剪取字符串,字符串的范围为从begin到末尾 public static String join (CharSequence delimiter, CharSequence... elements) 将字符串连接起来public static String join (CharSequence delimiter,Iterable<? extends CharSequence> elements) 将Collection中的字符串用给定的连接字符连接起来 public static String valueOf (int i) 返回 int 参数的字符串表示形式,参数还可为 long ,float ,double ,boolean ,char ,char []等public char [] toCharArray() 将字符串转换为数组public byte [] getbytes() 将字符串转换为新的字节数组String replace (char oldChar, char newChar) 它是通过用 newChar 替换此字符串中出现的所有 oldChar 得到的新的字符串 public String replace (CharSequence target,CharSequence replace) 替换字符串中的指定字符public String toLowerCase () 使用默认语言环境的规则将此 String 中的所有字符都转换为小写。 public String[] split(String regex)将字符串按照指定的分隔符分隔成数组 String intern () 返回字符串对象的规范化表示形式。 String trim () 返回字符串的副本,忽略前导空白和尾部空白。
1 2 3 4 5 6 7 8 9 10 class Solution { public void reverseString (char [] s) { int len=s.length; for (int i=0 ,j=len-1 ;i<j;++i,--j){ s[i] ^= s[j]; s[j] ^= s[i]; s[i] ^= s[j]; } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution { public String reverseStr (String s, int k) { char [] arr=s.toCharArray(); int len=arr.length; for (int i=0 ;i<len;i+=2 *k){ int start=i; int end=Math.min(len-1 ,start+k-1 ); for (;start<end;++start,--end){ arr[start] ^= arr[end]; arr[end] ^= arr[start]; arr[start] ^= arr[end]; } } return String.valueOf(arr); } }
请实现一个函数,把字符串 s 中的每个空格替换成”%20”。
1 2 3 4 5 6 7 8 9 10 11 class Solution { public String replaceSpace (String s) { StringBuilder sb = new StringBuilder (); for (int i=0 ;i<s.length();++i){ char c=s.charAt(i); if (c==' ' ) sb.append("%20" ); else sb.append(c); } return sb.toString(); } }
1 2 3 4 5 6 7 8 9 10 11 12 class Solution {public : string replaceSpace (string s) { for (int i=0 ;i<s.size ();i++){ if (s[i]==' ' ){ s.erase (s.begin ()+i); s.insert (i,"%20" ); } } return s; } };
给你一个字符串 s ,颠倒字符串中 单词 的顺序。单词 是由非空格字符组成的字符串。s 中使用至少一个空格将字符串中的 单词 分隔开。
返回 单词 顺序颠倒且 单词 之间用单个空格连接的结果字符串。
注意:输入字符串 s中可能会存在前导空格、尾随空格或者单词间的多个空格。返回的结果字符串中,单词间应当仅用单个空格分隔,且不包含任何额外的空格
1 2 3 4 5 6 7 8 class Solution { public String reverseWords (String s) { s=s.trim(); List<String> wordList = Arrays.asList(s.split(" +" )); Collections.reverse(wordList); return String.join(" " ,wordList); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 class Solution { public String reverseWords (String s) { StringBuilder sb = removeSpace(s); reverseString(sb, 0 , sb.length() - 1 ); reverseEachWord(sb); return sb.toString(); } private StringBuilder removeSpace (String s) { int start = 0 ; int end = s.length() - 1 ; while (s.charAt(start) == ' ' ) start++; while (s.charAt(end) == ' ' ) end--; StringBuilder sb = new StringBuilder (); while (start <= end) { char c = s.charAt(start); if (c != ' ' || sb.charAt(sb.length() - 1 ) != ' ' ) { sb.append(c); } start++; } return sb; } public void reverseString (StringBuilder sb, int start, int end) { while (start < end) { char temp = sb.charAt(start); sb.setCharAt(start, sb.charAt(end)); sb.setCharAt(end, temp); start++; end--; } } private void reverseEachWord (StringBuilder sb) { int start = 0 ; int end = 1 ; int n = sb.length(); while (start < n) { while (end < n && sb.charAt(end) != ' ' ) { end++; } reverseString(sb, start, end - 1 ); start = end + 1 ; end = start + 1 ; } } }
字符串的左旋转操作是把字符串前面的若干个字符转移到字符串的尾部。请定义一个函数实现字符串左旋转操作的功能。比如,输入字符串”abcdefg”和数字2,该函数将返回左旋转两位得到的结果”cdefgab”。
1 2 3 4 5 6 7 8 9 10 11 12 13 class Solution { public String reverseLeftWords (String s, int n) { StringBuilder sb=new StringBuilder (); int len=s.length(); for (int i=n;i<len;++i){ sb.append(s.charAt(i)); } for (int i=0 ;i<n;++i){ sb.append(s.charAt(i)); } return sb.toString(); } }
KMP算法(待补充) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Solution { public boolean repeatedSubstringPattern (String s) { int n= s.length(); for (int i=1 ;i*2 <=n;++i){ boolean match=true ; if (n%i==0 ){ for (int j=i;j<n;++j){ if (s.charAt(j)!=s.charAt(j-i)){ match=false ; break ; } } if (match==true ) return true ; } } return false ; } public boolean repeatedSubstringPattern1 (String s) { return (s + s).indexOf(s, 1 ) != s.length(); } }
栈与队列
请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(push、pop、peek、empty):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class MyQueue { private Deque<Integer> stackIn; private Deque<Integer> stackOut; public MyQueue () { stackIn=new ArrayDeque <>(); stackOut=new ArrayDeque <>(); } public void push (int x) { stackIn.push(x); } public int pop () { if (!stackOut.isEmpty()) return stackOut.pop(); else { while (!stackIn.isEmpty()){ stackOut.push(stackIn.pop()); } return stackOut.pop(); } } public int peek () { if (!stackOut.isEmpty()) return stackOut.peek(); else { while (!stackIn.isEmpty()){ stackOut.push(stackIn.pop()); } return stackOut.peek(); } } public boolean empty () { return stackIn.isEmpty()&&stackOut.isEmpty(); } }
请你仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(push、top、pop 和 empty)。
用队列模拟栈不能像栈模拟队列时那样的思路,这是队列和栈的性质决定的,用两个队列来模拟栈时,第二个队列的作用就是备份。当然我们也可以完全使用一个队列来模拟。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 class MyStack { Deque<Integer> queue1; Deque<Integer> queue2; public MyStack () { queue1= new ArrayDeque <>(); queue2= new ArrayDeque <>(); } public void push (int x) { queue2.offer(x); while (!queue1.isEmpty()){ queue2.offer(queue1.poll()); } Deque<Integer> temp=queue1; queue1=queue2; queue2=temp; } } public int pop () { return queue1.pop(); } public int top () { return queue1.peekFirst(); } public boolean empty () { return queue1.isEmpty(); } }
有效的括号
给定一个只包括 ‘(‘,’)’,’{‘,’}’,’[‘,’]’ 的字符串,判断字符串是否有效。
有效字符串需满足:
左括号必须用相同类型的右括号闭合。
左括号必须以正确的顺序闭合。
注意空字符串可被认为是有效字符串。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution { public boolean isValid (String s) { int len= s.length(); if (len%2 !=0 ) return false ; Deque<Character> stack=new ArrayDeque <>(); Map<Character,Character> map=new HashMap <>(); map.put('(' ,')' ); map.put('{' ,'}' ); map.put('[' ,']' ); for (int i=0 ;i<len;++i){ char c=s.charAt(i); if (map.containsKey(c)){ stack.push(c); } else { if (stack.size()==0 || map.get(stack.pop())!=c) return false ; } } return stack.isEmpty(); } }
给出由小写字母组成的字符串 S,重复项删除操作会选择两个相邻且相同的字母,并删除它们。在 S 上反复执行重复项删除操作,直到无法继续删除。在完成所有重复项删除操作后返回最终的字符串。答案保证唯一。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution { public String removeDuplicates (String s) { int len=s.length(); if (len<2 ) return s; Deque<Character> stack=new ArrayDeque <>(); for (int i=0 ;i<len;++i){ char ch=s.charAt(i); if (!stack.isEmpty()&&stack.peek()==ch){ stack.pop(); } else stack.push(ch); } len=stack.size(); StringBuilder res=new StringBuilder (); for (int i=0 ;i<len;++i){ res.append(stack.pollLast()); } return res.toString(); } }
逆波兰表达式求值
有效的算符包括 +、-、*、/ 。每个运算对象可以是整数,也可以是另一个逆波兰表达式。
注意 两个整数之间的除法只保留整数部分。
可以保证给定的逆波兰表达式总是有效的。换句话说,表达式总会得出有效数值且不存在除数为 0 的情况。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Solution { public int evalRPN (String[] tokens) { Set<String> operator=new HashSet <>(); operator.add("+" ); operator.add("-" ); operator.add("/" ); operator.add("*" ); Deque<String> st=new ArrayDeque <>(); int len=tokens.length; for (int i=0 ;i<len;++i){ String op=tokens[i]; if (operator.contains(op)){ int b = Integer.parseInt((st.pop())); int a = Integer.parseInt((st.pop())); switch (op){ case "+" : st.push(String.valueOf(a+b));break ; case "-" : st.push(String.valueOf(a-b));break ; case "*" : st.push(String.valueOf(a*b));break ; case "/" : st.push(String.valueOf(a/b));break ; } } else { st.push(op); } } return Integer.parseInt(st.peek()); } }
给你一个字符串 path ,表示指向某一文件或目录的 Unix 风格 绝对路径 (以 ‘/‘ 开头),请你将其转化为更加简洁的规范路径。
在 Unix 风格的文件系统中,一个点(.)表示当前目录本身;此外,两个点 (..) 表示将目录切换到上一级(指向父目录);两者都可以是复杂相对路径的组成部分。任意多个连续的斜杠(即,’//‘)都被视为单个斜杠 ‘/‘ 。 对于此问题,任何其他格式的点(例如,’…’)均被视为文件/目录名称。
请注意,返回的 规范路径 必须遵循下述格式:
始终以斜杠 ‘/‘ 开头。
ArrayDeque类的使用详解 - 路迢迢 - 博客园 (cnblogs.com)
如果会使用String的split( )函数,那么这个题目会变得非常简单。只需要利用栈,对特殊情况加以处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class Solution { public String simplifyPath (String path) { StringBuilder res = new StringBuilder (); Deque<String> stack=new ArrayDeque <String>(); String[] dirs=path.split("/" ); int len=path.length(); for (String name:dirs){ if (".." .equals(name)){ if (!stack.isEmpty()) stack.pop(); }else if (name.length()>0 &&!"." .equals(name)){ stack.push(name); } } if (stack.isEmpty()){ res.append('/' ); } else { while (!stack.isEmpty()){ res.append('/' ); res.append(stack.pollLast()); } } return res.toString(); } }
二叉树 N叉树的前序遍历
给定一个 n 叉树的根节点 root ,返回 其节点值的 前序遍历 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class Solution { List<Integer> res=new ArrayList <>(); public List<Integer> preorder (Node root) { if (root==null ) return res; res.add(root.val); for (Node node : root.children){ preorder(node); } return res; } } class Solution { public List<Integer> preorder (Node root) { List<Integer> res = new ArrayList <Integer>(); Stack<Node> stack = new Stack <Node>(); if (root == null ) return res; stack.push(root); while (!stack.isEmpty()) { Node node = stack.pop(); res.add (node.val); for (int i = node.children.size()-1 ;i>= 0 ;i--) { stack.add(node.children.get(i)); } } return res; } }
二叉树的层序遍历 二叉树的层序遍历
给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution { public List<List<Integer>> levelOrder (TreeNode root) { if (root==null ) return new ArrayList <>(); List<List<Integer>> res=new ArrayList <>(); Queue<TreeNode> queue=new LinkedList <>(); queue.add(root); while (!queue.isEmpty()){ int count=queue.size(); List<Integer> list=new ArrayList <Integer>(); while (count>0 ){ TreeNode node=queue.poll(); list.add(node.val); if (node.left!=null ) queue.add(node.left); if (node.right!=null ) queue.add(node.right); count--; } res.add(list); } return res; } }
给你二叉树的根节点 root ,返回其节点值 自底向上的层序遍历 。 (即按从叶子节点所在层到根节点所在的层,逐层从左向右遍历)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution { public List<List<Integer>> levelOrderBottom (TreeNode root) { if (root==null ) return new ArrayList <>(); LinkedList<List<Integer>> res=new LinkedList <>(); Queue<TreeNode> queue=new LinkedList <>(); queue.add(root); while (!queue.isEmpty()){ int count=queue.size(); List<Integer> list=new ArrayList <Integer>(); while (count>0 ){ TreeNode node=queue.poll(); list.add(node.val); if (node.left!=null ) queue.add(node.left); if (node.right!=null ) queue.add(node.right); count--; } res.addFirst(list); } return res; } }
二叉树的右视图
给定一个二叉树的 根节点 root,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution { public List<Integer> rightSideView (TreeNode root) { if (root==null ) return new LinkedList <>(); List<Integer> res=new ArrayList <>(); Deque<TreeNode> queue=new ArrayDeque <>(); queue.add(root); while (!queue.isEmpty()){ int count = queue.size(); for (;count>0 ;--count){ TreeNode node = queue.poll(); if (count==1 ) res.add(node.val); if (node.left!=null ) queue.add(node.left); if (node.right!=null ) queue.add(node.right); } } return res; } }
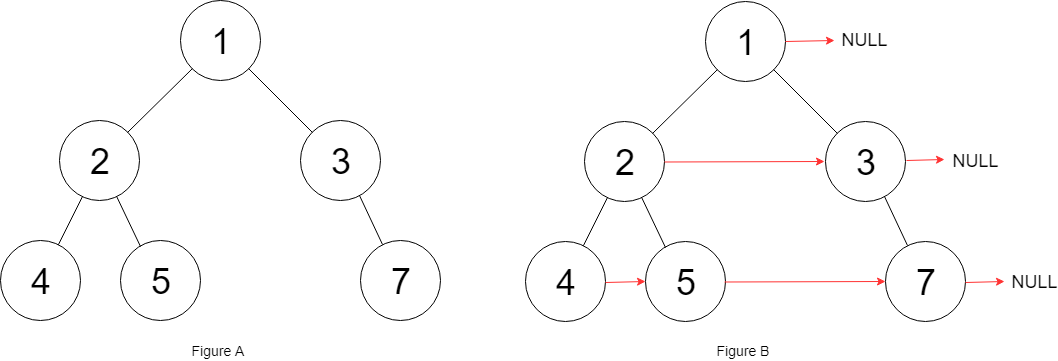
填充每个节点的下一个右侧节点指针 II
填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
初始状态下,所有 next 指针都被设置为 NULL。
给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。
二叉树的递归要考虑使用的条件:
终止条件: root=null即终止
我们可以将本题归结为二叉树的遍历问题,只不过处理逻辑变为交换左右子节点。本题可以考虑使用先序遍历和后序遍历。但中序遍历会稍稍不同(因为按照传统的写法,会造成有些结点翻转两次)。既然我们可以使用递归的先序和后序遍历,我们同样可以使用迭代法来求解本题(DFS,BFS均可)。
1 2 3 4 5 6 7 8 9 10 11 12 13 class Solution { public TreeNode invertTree (TreeNode node) { if (node==null ) return null ; TreeNode temp=node.left; node.left=node.right; node.right=temp; TreeNode left=invertTree(node.left); TreeNode right=invertTree(node.right); return node; } }
迭代解法(先序遍历)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution {public : TreeNode* invertTree (TreeNode* root) { if (root == NULL ) return root; stack<TreeNode*> st; st.push (root); while (!st.empty ()) { TreeNode* node = st.top (); st.pop (); swap (node->left, node->right); if (node->right) st.push (node->right); if (node->left) st.push (node->left); } return root; } };
给你一个二叉树的根节点 root , 检查它是否轴对称。
迭代法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution { public boolean isSymmetric (TreeNode root) { return checkMirro(root.left,root.right); } private boolean checkMirro (TreeNode node1, TreeNode node2) { if (node1 == null && node2 == null ) return true ; if (node1 == null || node2 == null ) return false ; if (node1.val!=node2.val) return false ; return checkMirro(node1.left, node2.right) && checkMirro(node1.right, node2.left); } }
二叉树的最大深度 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution { public int maxDepth (TreeNode root) { if (root==null ) return 0 ; int leftDepth=maxDepth(root.left)+1 ; int rightDepth=maxDepth(root.right)+1 ; return leftDepth>rightDepth?leftDepth:rightDepth; } } class Solution { public int maxDepth (TreeNode root) { if (root == null ) { return 0 ; } int level = 0 ; Queue<TreeNode> queue = new LinkedList <TreeNode>(); queue.add(root); while (!queue.isEmpty()) { int size = queue.size(); level++; for (int i = 0 ; i < size; i++) { TreeNode node = queue.remove(); if (node.left != null ) queue.add(node.left); if (node.right != null ) queue.add(node.right); } } return level; } }
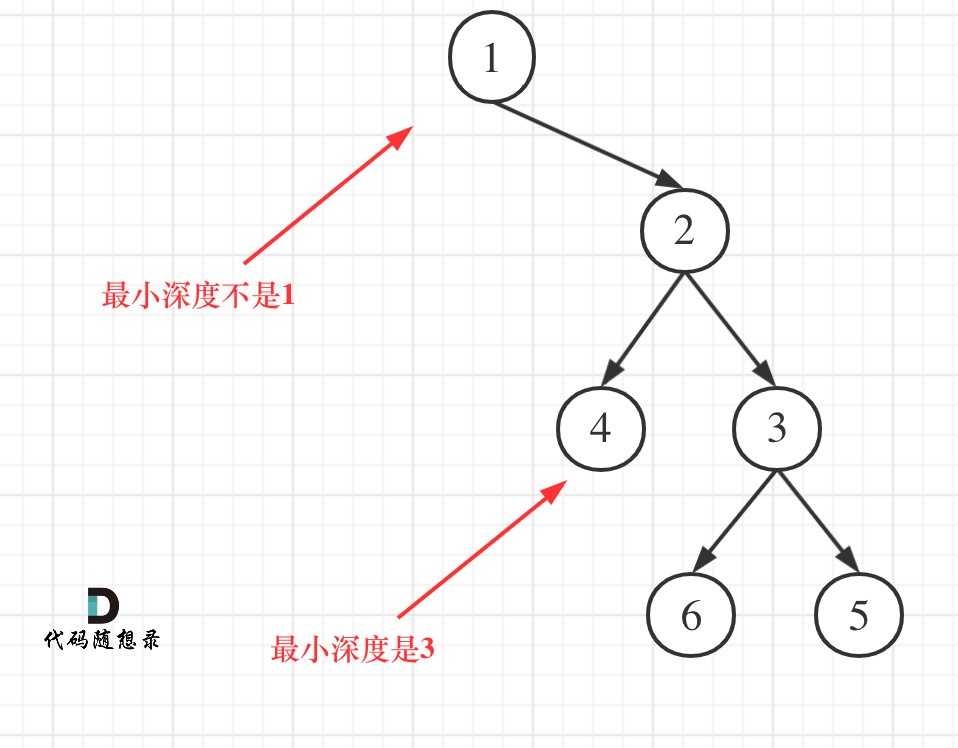
求二叉树的最小深度和求二叉树的最大深度的差别主要在于处理左右孩子不为空的逻辑。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class Solution { public int minDepth (TreeNode root) { if (root==null ) return 0 ; if (root.left==null &&root.right!=null ) return minDepth(root.right)+1 ; else if (root.left!=null &&root.right==null ) return minDepth(root.left)+1 ; return Math.min(minDepth(root.left),minDepth(root.right))+1 ; } } class Solution { public int minDepth (TreeNode root) { if (root == null ) { return 0 ; } int level = 0 ; Queue<TreeNode> queue = new LinkedList <TreeNode>(); queue.add(root); while (!queue.isEmpty()) { int size = queue.size(); level++; for (int i = 0 ; i < size; i++) { TreeNode node = queue.remove(); if (node.left == null &&node.right==null ) return level; else { if (node.left!=null ) queue.add(node.left); if (node.right!=null ) queue.add(node.right); } } } return level; } }
完全二叉树的节点个数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class Solution { public int countNodes (TreeNode root) { if (root==null ) return 0 ; int leftcount=countNodes(root.left); int rightcount=countNodes(root.right); return leftcount+rightcount+1 ; } } class Solution { public int countNodes (TreeNode root) { if (root==null ) return 0 ; int count=0 ; Queue<TreeNode> queue=new LinkedList <>(); queue.add(root); while (!queue.isEmpty()){ int size=queue.size(); for (int i=0 ;i<size;++i){ TreeNode node=queue.remove(); count++; if (node.left!=null &&node.right==null ) return 2 *count; if (node.left==null &&node.right==null ) return 2 *count-1 ; queue.add(node.left); queue.add(node.right); } } return count; } }
高度平衡的二叉树:一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过1。
我们可以将问题归结为这样的形式:如果一个二叉树是高度平衡二叉树,那么它的左右子树为高度平衡二叉树且左右子树的高度差不超过1;
二叉树节点的深度:指从根节点到该节点的最长简单路径边的条数。
二叉树节点的高度:指从该节点到叶子节点的最长简单路径边的条数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class Solution { public boolean isBalanced (TreeNode root) { if (root==null ) return true ; return isBalanced(root.left)&&isBalanced(root.right)&&Math.abs(treeDepth(root.left)-treeDepth(root.right))<=1 ; } private int treeDepth (TreeNode node) { if (node==null ) return 0 ; int leftDepth=treeDepth(node.left)+1 ; int rightDepth=treeDepth(node.right)+1 ; return leftDepth>rightDepth?leftDepth:rightDepth; } } class Solution { public boolean isBalanced (TreeNode root) { return height(root) >= 0 ; } public int height (TreeNode root) { if (root == null ) { return 0 ; } int leftHeight = height(root.left); int rightHeight = height(root.right); if (leftHeight == -1 || rightHeight == -1 || Math.abs(leftHeight - rightHeight) > 1 ) { return -1 ; } else { return Math.max(leftHeight, rightHeight) + 1 ; } } }
给你一个二叉树的根节点 root ,按 任意顺序 ,返回所有从根节点到叶子节点的路径。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 class Solution { List<String> res=new ArrayList <>(); public List<String> binaryTreePaths (TreeNode root) { String path=String.valueOf(root.val); if (root.left==null &&root.right==null ) res.add(path); if (root.left!=null ) helper(root.left,path); if (root.right!=null ) helper(root.right,path); return res; } private void helper (TreeNode node,String path) { StringBuilder pathbuff=new StringBuilder (path); pathbuff.append("->" ).append(String.valueOf(node.val)); if (node.left==null &&node.right==null ) { res.add(pathbuff.toString()); return ; } if (node.left!=null ) helper(node.left,pathbuff.toString()); if (node.right!=null ) helper(node.right,pathbuff.toString()); } } class Solution { public void traversal (TreeNode cur, String path, List<String> result) { path += cur.val; if (cur.left == null && cur.right == null ) { result.add(path); return ; } if (cur.left!=null ) traversal(cur.left, path + "->" , result); if (cur.right!=null ) traversal(cur.right, path + "->" , result); } public List<String> binaryTreePaths (TreeNode root) { List<String> result = new LinkedList <>(); String path = "" ; if (root == null ) return result; traversal(root, path, result); return result; } }
给定二叉树的根节点 root ,返回所有左叶子之和。
递归法
确定递归函数的参数和返回值
确定终止条件
确定单层递归的逻辑
当遇到左叶子节点的时候,记录数值,然后通过递归求取左子树左叶子之和,和 右子树左叶子之和,相加便是整个树的左叶子之和。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Solution { public int sumOfLeftLeaves (TreeNode root) { int sum=0 ; if (root.left!=null &&isLeafNode(root.left)) sum+=root.left.val; if (root.left!=null ) sum+=sumOfLeftLeaves(root.left); if (root.right!=null ) sum+=sumOfLeftLeaves(root.right); return sum; } private boolean isLeafNode (TreeNode node) { return node.left==null &&node.right==null ; } } class Solution { public int sumOfLeftLeaves (TreeNode root) { if (root == null ) return 0 ; Stack<TreeNode> stack = new Stack <> (); stack.add(root); int result = 0 ; while (!stack.isEmpty()) { TreeNode node = stack.pop(); if (node.left != null && node.left.left == null && node.left.right == null ) { result += node.left.val; } if (node.right != null ) stack.add(node.right); if (node.left != null ) stack.add(node.left); } return result; } }
找树左下角的值
给定一个二叉树的 根节点 root,请找出该二叉树的 最底层 最左边 节点的值。
递归的核心在本题中得到再一次的展现:
确定单层递归的逻辑
确定参数和返回值
确定终止条件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 class Solution { public int findBottomLeftValue (TreeNode root) { Queue<TreeNode> queue = new LinkedList <>(); queue.offer(root); int res = 0 ; while (!queue.isEmpty()){ int size = queue.size(); for (int i = 0 ; i < size; i++) { TreeNode node=queue.poll(); if (i==0 &&node.left==null &&node.right==null ) res=node.val; if (node.left!=null ) queue.offer(node.left); if (node.right!=null ) queue.offer(node.right); } } return res; } } class Solution { int maxLevel=-1 ; int res; public int findBottomLeftValue (TreeNode root) { traverse(root,0 ); return res; } private void traverse (TreeNode root,int level) { if (root==null ) return ; if (maxLevel<level){ maxLevel=level; res=root.val; } traverse(root.left,level+1 ); traverse(root.right,level+1 ); } }
给你二叉树的根节点 root 和一个表示目标和的整数 targetSum 。判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。如果存在,返回 true ;否则,返回 false 。
1 2 3 4 5 6 7 8 class Solution { public boolean hasPathSum (TreeNode root, int targetSum) { if (root==null ) return false ; targetSum-=root.val; if (targetSum==0 &&root.left==null &&root.right==null ) return true ; return hasPathSum(root.left,targetSum)||hasPathSum(root.right,targetSum); } }
给你二叉树的根节点 root 和一个整数目标和 targetSum ,找出所有 从根节点到叶子节点 路径总和等于给定目标和的路径。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution { List<List<Integer>> res =new ArrayList <>(); List<Integer> path=new ArrayList <>(); public List<List<Integer>> pathSum (TreeNode root, int targetSum) { traversePath(root,targetSum,path); return res; } private void traversePath (TreeNode root, int targetSum,List<Integer> path) { if (root==null ) return ; targetSum-=root.val; path.add(root.val); if (targetSum==0 &&root.left==null &&root.right==null ) { List<Integer> list=new ArrayList <>(); list.addAll(path); res.add(list); path.remove(path.size()-1 ); return ; } traversePath(root.left,targetSum,path); traversePath(root.right,targetSum,path); path.remove(path.size()-1 ); } }
给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。
在中序序列和后序序列中划分左右子树,最后分别递归左子树的两个序列和右子树的两个序列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Solution { HashMap<Integer,Integer> map=new HashMap <>(); public TreeNode buildTree (int [] inorder, int [] postorder) { int len=inorder.length; for (int i=0 ;i<len;++i){ map.put(inorder[i],i); } return helper(inorder,postorder,0 ,len-1 ,0 ,len-1 ); } private TreeNode helper (int [] inorder,int [] postorder, int post_left,int post_right,int in_left,int in_right) { if (in_left>in_right||post_left>post_right) return null ; TreeNode root=new TreeNode (postorder[post_right]); int in_rootIndex=map.get(postorder[post_right]); int post_rightIndex=post_left+in_rootIndex-in_left; root.left= helper(inorder,postorder,post_left,post_rightIndex-1 ,in_left,in_rootIndex-1 ); root.right=helper(inorder,postorder,post_rightIndex,post_right-1 ,in_rootIndex+1 ,in_right); return root; } }
给定一个不重复的整数数组 nums 。 最大二叉树 可以用下面的算法从 nums 递归地构建:
创建一个根节点,其值为 nums 中的最大值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution { public TreeNode constructMaximumBinaryTree (int [] nums) { int len=nums.length; return helper(nums,0 ,len-1 ); } private TreeNode helper (int [] nums, int left,int right) { if (left>right) return null ; int maxIndex=findMaxIndex(nums,left,right); TreeNode node=new TreeNode (nums[maxIndex]); node.left=helper(nums,left,maxIndex-1 ); node.right=helper(nums,maxIndex+1 ,right); return node; } private int findMaxIndex (int [] nums,int left,int right) { int maxIndex=left; int max=nums[left]; for (int i=left+1 ;i<=right;++i){ if (max<nums[i]) { max=nums[i]; maxIndex=i; } } return maxIndex; } }
给你两棵二叉树: root1 和 root2 。
想象一下,当你将其中一棵覆盖到另一棵之上时,两棵树上的一些节点将会重叠(而另一些不会)。你需要将这两棵树合并成一棵新二叉树。合并的规则是:如果两个节点重叠,那么将这两个节点的值相加作为合并后节点的新值;否则,不为 null 的节点将直接作为新二叉树的节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Solution { public TreeNode mergeTrees (TreeNode root1, TreeNode root2) { if (root1==null ||root2==null ) root1= (root1==null ?root2:root1); else if (root1!=null &&root2!=null ) { root1.val+=root2.val; root1.left=mergeTrees(root1.left,root2.left); root1.right=mergeTrees(root1.right,root2.right); } return root1; } }
给定二叉搜索树(BST)的根节点 root 和一个整数值 val。
你需要在 BST 中找到节点值等于 val 的节点。 返回以该节点为根的子树。 如果节点不存在,则返回 null 。
1 2 3 4 5 6 class Solution { public TreeNode searchBST (TreeNode root, int val) { if (root==null ||root.val==val) return root; return val>root.val? searchBST(root.right,val):searchBST(root.left,val); } }
验证二叉搜索树的关键是:中序遍历为递增的序列 !
若本题使用递归法,则可以将单层递归的逻辑归结为:
验证左子树为递增的序列
比较最后一个遍历到的值与当前节点的值,验证是否递增
验证右子树为递增的序列
1 2 3 4 5 6 7 8 9 10 11 12 13 class Solution { private double preVal = -Double.MAX_VALUE; public boolean isValidBST (TreeNode root) { if (root==null ) return true ; if (isValidBST(root.left)){ if (preVal<root.val){ preVal=root.val; return isValidBST(root.right); } } return false ; } }
给你一个二叉搜索树的根节点 root ,返回 树中任意两不同节点值之间的最小差值 。
差值是一个正数,其数值等于两值之差的绝对值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution { private int min=Integer.MAX_VALUE; private int preValue=-1 ; public int getMinimumDifference (TreeNode root) { traverse(root); return min; } public void traverse (TreeNode node) { if (node==null ) return ; traverse(node.left); if (preValue==-1 ) preValue=node.val; else { min=Math.min(min,node.val-preValue); preValue=node.val; } traverse(node.right); } }
给你一个含重复值的二叉搜索树(BST)的根节点 root ,找出并返回 BST 中的所有 众数(即,出现频率最高的元素)。
如果树中有不止一个众数,可以按 任意顺序 返回。
假定 BST 满足如下定义:
结点左子树中所含节点的值 小于等于 当前节点的值
当我们看到统计频率的时候,应该下意识的想到哈希表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 class Solution { private int preValue; private int MaxFreq; private int frequence; private LinkedList<Integer> list=new LinkedList <>(); public int [] findMode(TreeNode root) { traverse(root); int size=list.size(); int [] res=new int [list.size()]; for (int i=0 ;i<size;++i){ res[i]=list.get(i); } return res; } public void traverse (TreeNode node) { if (node==null ) return ; traverse(node.left); update(node.val); traverse(node.right); } private void update (int val) { if (val==preValue){ frequence++; }else { preValue=val; frequence=1 ; } if (MaxFreq==frequence){ list.add(val); } else if (MaxFreq<frequence){ list.clear(); MaxFreq=frequence; list.add(val); } } }
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
既然是求公共的祖先节点,我们应该首先想到的是从下至上的遍历,而后序遍历就是天然的从下至上的遍历,它首先检查到的一定是叶子节点。在后序遍历过程中,会出现两种情况:
如果找到一个节点,发现左子树出现结点p,右子树出现节点q,或者 左子树出现结点q,右子树出现节点p,那么该节点就是节点p和q的最近公共祖先。 节点本身p(q),它拥有一个子孙节点q(p)。,那么此时最近公共祖先是p(q);
这两个情况说明了当我们在后序遍历的过程中遇到一个node,它等于p或者q,那么就没有必要再搜索它的子节点了,因为最近公共祖先要么是它自身,要么在它的某个祖先。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution { public TreeNode lowestCommonAncestor (TreeNode root, TreeNode p, TreeNode q) { if (root==null ) return null ; if (root==p||root==q) return root; TreeNode left= lowestCommonAncestor(root.left,p,q); TreeNode right= lowestCommonAncestor(root.right,p,q); if (left!=null &&right!=null ) return root; if (left!=null )return left; if (right!=null ) return right; return null ; } }
我们可以利用二叉搜索树的特性,若p,q的两个节点值都大于root,那么它们一定位于root的右子树,如都小于root的值,则它们一定位于root的左子树,两种情况都不满足,则分别位于两个子树上,那么最近公共祖先一定是root。
1 2 3 4 5 6 7 8 class Solution { public TreeNode lowestCommonAncestor (TreeNode root, TreeNode p, TreeNode q) { if (root.val==p.val||root.val==q.val) return root; if (p.val>root.val&&q.val>root.val) return lowestCommonAncestor(root.right,p,q); if (p.val<root.val&&q.val<root.val) return lowestCommonAncestor(root.left,p,q); else return root; } }
递归解法:
确定递归函数参数以及返回值:参数就是根节点指针,以及要插入元素,这里递归函数的返回值为当前节点root
确定终止条件:此处终止条件为遇到空节点,也就是要插入的位置,此处我们返回一个新的节点node
确定单层递归的逻辑:要明确,需要遍历整棵树么?别忘了这是搜索树,遍历整棵搜索树简直是对搜索树的侮辱,哈哈。
搜索树是有方向了,可以根据插入元素的数值,决定递归方向。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class Solution { public TreeNode insertIntoBST (TreeNode root, int val) { if (root==null ) return new TreeNode (val); else if (val>root.val) root.right=insertIntoBST(root.right,val); else if (val<root.val) root.left=insertIntoBST(root.left,val); return root; } } class Solution { public TreeNode insertIntoBST (TreeNode root, int val) { if (root == null ) return new TreeNode (val); TreeNode newRoot = root; TreeNode pre = root; while (root != null ) { pre = root; if (root.val > val) { root = root.left; } else if (root.val < val) { root = root.right; } } if (pre.val > val) { pre.left = new TreeNode (val); } else { pre.right = new TreeNode (val); } return newRoot; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution { public TreeNode deleteNode (TreeNode root, int key) { if (root==null ) return null ; else if (key<root.val) root.left = deleteNode(root.left,key); else if (key>root.val) root.right = deleteNode(root.right,key); if (root.val==key) { if (root.right==null ) return root.left; else { TreeNode pre=root.right; TreeNode cur=root.right; while (cur.left!=null ) { pre=cur; cur=cur.left; } if (pre==cur) cur.left=root.left; else { pre.left=cur.right; cur.left=root.left; cur.right=root.right; } return cur; } } return root; } }
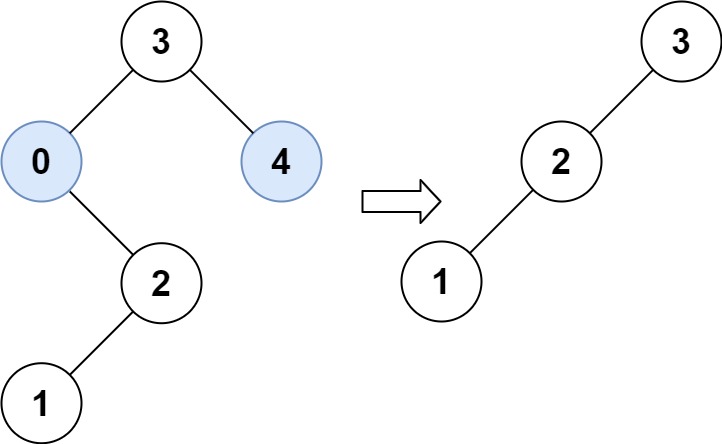
给你二叉搜索树的根节点 root ,同时给定最小边界low 和最大边界 high。通过修剪二叉搜索树,使得所有节点的值在[low, high]中。修剪树 不应该 改变保留在树中的元素的相对结构 (即,如果没有被移除,原有的父代子代关系都应当保留)。 可以证明,存在 唯一的答案 。
所以结果应当返回修剪好的二叉搜索树的新的根节点。注意,根节点可能会根据给定的边界发生改变。
1 2 输入:root = [3,0,4,null,2,null,null,1], low = 1, high = 3 输出:[3,2,null,1]
这个题,还是在强调,问题本身,就是答案的核心,三种遍历都是递归,而递归的本质就是用相同的方式处理子问题,做完#776后,可以再感受一下,做这种二叉树的题目,什么是第一要素。
打开思路以后,其实就会发现,root可能会在范围内,也有可能不在,讨论一下:
如果在范围内,那么说明root是要保留的,也就是说不用处理root,处理左右子树就可以了。
如果不再范围内,假如root-val > low,且根据BST性质,就会发现,左子树和root都在区间外,要保留的只可能是处理后的右子树。
所以,做这种题,就是先考虑:
是否能用题目的定义
如果可以用,那么是否可以用题目定义处理子问题(子树)
如果可以处理子问题,是否可以用子问题结果凑出原定义
多说一句,因为本身题目给的API就是问题的答案,如果可以凑出来,实际上就是求解过程。
递归将问题的复杂性约束在了当前遍历到的单个节点上
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 class Solution { public TreeNode trimBST (TreeNode root, int low, int high) { if (root==null ) return null ; if (root.val<low) return trimBST(root.right,low,high); if (root.val>high) return trimBST(root.left,low,high); root.left=trimBST(root.left,low,high); root.right=trimBST(root.right,low,high); return root; } } class Solution {public : TreeNode* trimBST(TreeNode* root, int L, int R) { if (!root) return nullptr; while (root != nullptr && (root->val < L || root->val > R)) { if (root->val < L) root = root->right; else root = root->left; } TreeNode *cur = root; while (cur != nullptr) { while (cur->left && cur->left->val < L) { cur->left = cur->left->right; } cur = cur->left; } cur = root; while (cur != nullptr) { while (cur->right && cur->right->val > R) { cur->right = cur->right->left; } cur = cur->right; } return root; } };
给你一个整数数组 nums ,其中元素已经按 升序 排列,请你将其转换为一棵 高度平衡 二叉搜索树。
高度平衡 二叉树是一棵满足「每个节点的左右两个子树的高度差的绝对值不超过 1 」的二叉树。
在使用递归时要考虑几个问题:
相似子问题是什么? —— 对于二叉树而言,相似子问题一般可以归结为节点的左右子树上的问题。
单层递归的逻辑是什么? —— 建立根节点,划分左右子树
递归的终止条件是什么?—— left>right
递归的参数和返回值是什么?—— 返回本次递归构造的节点。参数为数组,需要构造的边界
1 2 3 4 5 6 7 8 9 10 11 12 13 class Solution { public TreeNode sortedArrayToBST (int [] nums) { return build(nums,0 ,nums.length-1 ); } private TreeNode build (int [] nums,int left,int right) { if (left>right) return null ; int mid=(left+right)/2 ; TreeNode node = new TreeNode (nums[mid]); node.left= build(nums,left,mid-1 ); node.right= build(nums,mid+1 ,right); return node; } }
给出二叉 搜索 树的根节点,该树的节点值各不相同,请你将其转换为累加树(Greater Sum Tree),使每个节点 node 的新值等于原树中大于或等于 node.val 的值之和。
提醒一下,二叉搜索树满足下列约束条件:
节点的左子树仅包含键 小于 节点键的节点。
右中左的遍历方向,进行累加,并将结果写到节点中
1 2 3 4 5 6 7 8 9 10 11 12 13 class Solution { ArrayList<Integer> list = new ArrayList <>(); int sum=0 ; int count; public TreeNode convertBST (TreeNode root) { if (root==null ) return null ; convertBST(root.right); sum+=root.val; root.val=sum; convertBST(root.left); return root; } }
回溯算法理论基础 回溯的本质是穷举,穷举所有可能,然后选出我们想要的答案 ,如果想让回溯法高效一些,可以加一些剪枝的操作,但也改不了回溯法就是穷举的本质。
组合问题:N个数里面按一定规则找出k个数的集合
切割问题:一个字符串按一定规则有几种切割方式
子集问题:一个N个数的集合里有多少符合条件的子集
排列问题:N个数按一定规则全排列,有几种排列方式
棋盘问题:N皇后,解数独等等
回溯法解决的问题都可以抽象为树形结构 ,是的,我指的是所有回溯法的问题都可以抽象为树形结构!因为回溯法解决的都是在集合中递归查找子集,集合的大小就构成了树的宽度,递归的深度,都构成的树的深度 。递归就要有终止条件,所以必然是一棵高度有限的树(N叉树)。
解决⼀个回溯问题,实际上就是⼀个决策树的遍历过程。你只需要思考 3 个问题:
1、路径:也就是已经做出的选择。
1 2 3 4 5 6 7 8 result = [] def backtrack (路径, 选择列表) : if 满⾜结束条件: result.add(路径) return for 选择 in 选择列表: 做选择 backtrack(路径, 选择列表) 撤销选择
全排列问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution { List<List<Integer>> res=new LinkedList <>(); List<List<Integer>> permute (int [] nums) { LinkedList<Integer> track = new LinkedList <>(); backtrack(nums,track); return res; } void backtrack (int [] nums,LinkedList<Integer>track) { if (track.size()==nums.length) { res.add(new LinkedList (track)); } for (int i:nums){ if (track.contains(i)) continue ; track.add(i); backtrack(nums,track); track.removeLast(); } } }
须说明的是,不管怎么优化,都符合回溯框架,⽽且时间复杂度都不 可能低于 O(N!),因为穷举整棵决策树是⽆法避免的。这也是回溯算法的⼀ 个特点,不像动态规划存在重叠⼦问题可以优化,回溯算法就是纯暴⼒穷
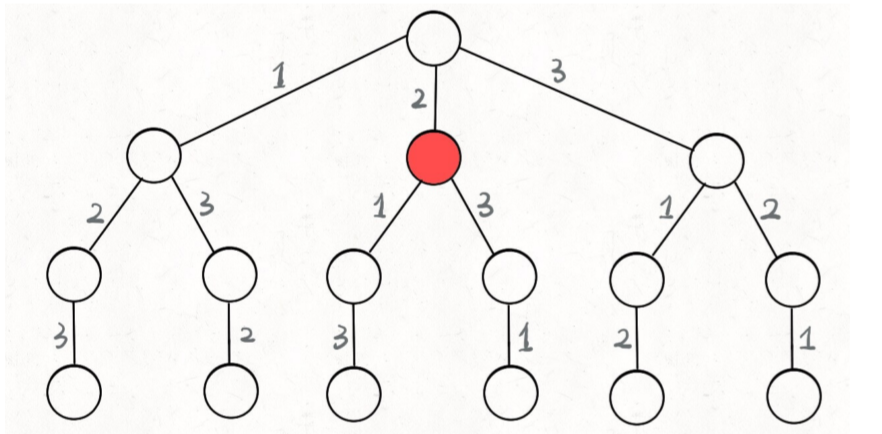
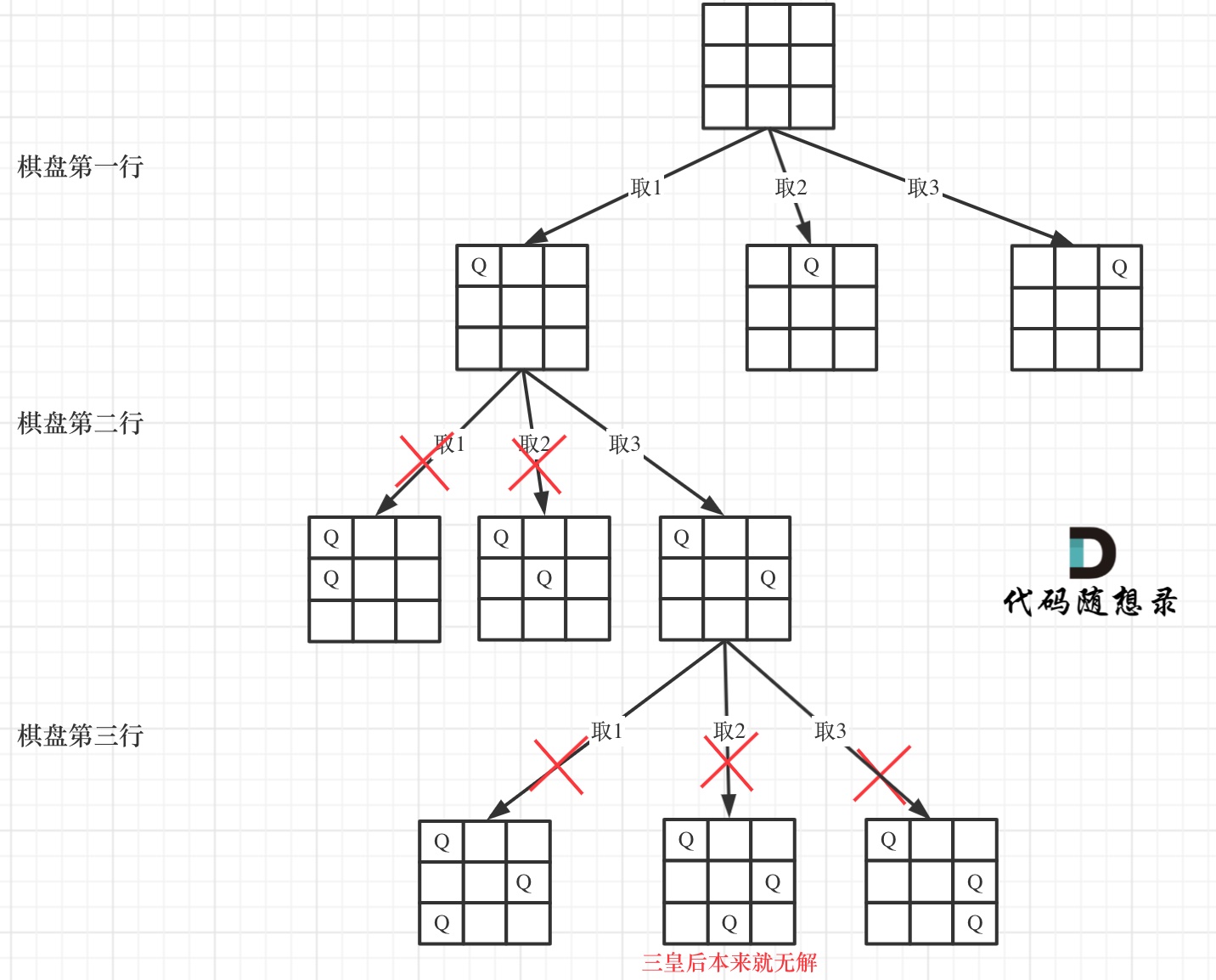
N 皇后问题 给你⼀个 N×N 的棋盘,让你放置 N 个 皇后,使得它们不能互相攻击。皇后可以攻击同⼀⾏、同⼀列、左上左下右上右下四个⽅向的任意单位。这个问题本质上跟全排列问题差不多,决策树的每⼀层表⽰棋盘上的每⼀ ⾏;每个节点可以做出的选择是,在该⾏的任意⼀列放置⼀个皇后。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 vector<vector<string>> res; vector<vector<string>> solveNQueens (int n) { vector<string> board (n, string(n, '.' )) ; backtrack (board, 0 ); return res; } void backtrack (vector<string>& board, int row) if (row == board.size ()) { res.push_back (board); return ; } int n = board[row].size (); for (int col = 0 ; col < n; col++){ if (!isValid (board, row, col)) continue ; board[row][col] = 'Q' ; backtrack (board, row + 1 ); board[row][col] = '.' ; } } bool isValid (vector<string>& board, int row, int col) int n = board.size (); for (int i = 0 ; i < n; i++) { if (board[i][col] == 'Q' ) return false ; } for (int i = row - 1 , j = col + 1 ; i >= 0 && j < n; i--, j++) { if (board[i][j] == 'Q' ) return false ; } for (int i = row - 1 , j = col - 1 ; i >= 0 && j >= 0 ; i--, j--) { if (board[i][j] == 'Q' ) return false ; } return true ; }
有的时候,我们并不想得到所有合法的答案,只想要⼀个答案,怎么办呢? ⽐如解数独的算法,找所有解法复杂度太⾼,只要找到⼀种解法就可以。
写 backtrack 函数时,需要维护⾛过的「路径」和当前可以做的「选择列 表」,当触发「结束条件」时,将「路径」记⼊结果集。
某种程度上说,动态规划的暴⼒求解阶段就是回溯算法。只是有的问题具有 重叠⼦问题性质,可以⽤ dp table 或者备忘录优化,将递归树⼤幅剪枝,这 就变成了动态规划。⽽今天的两个问题,都没有重叠⼦问题,也就是回溯算
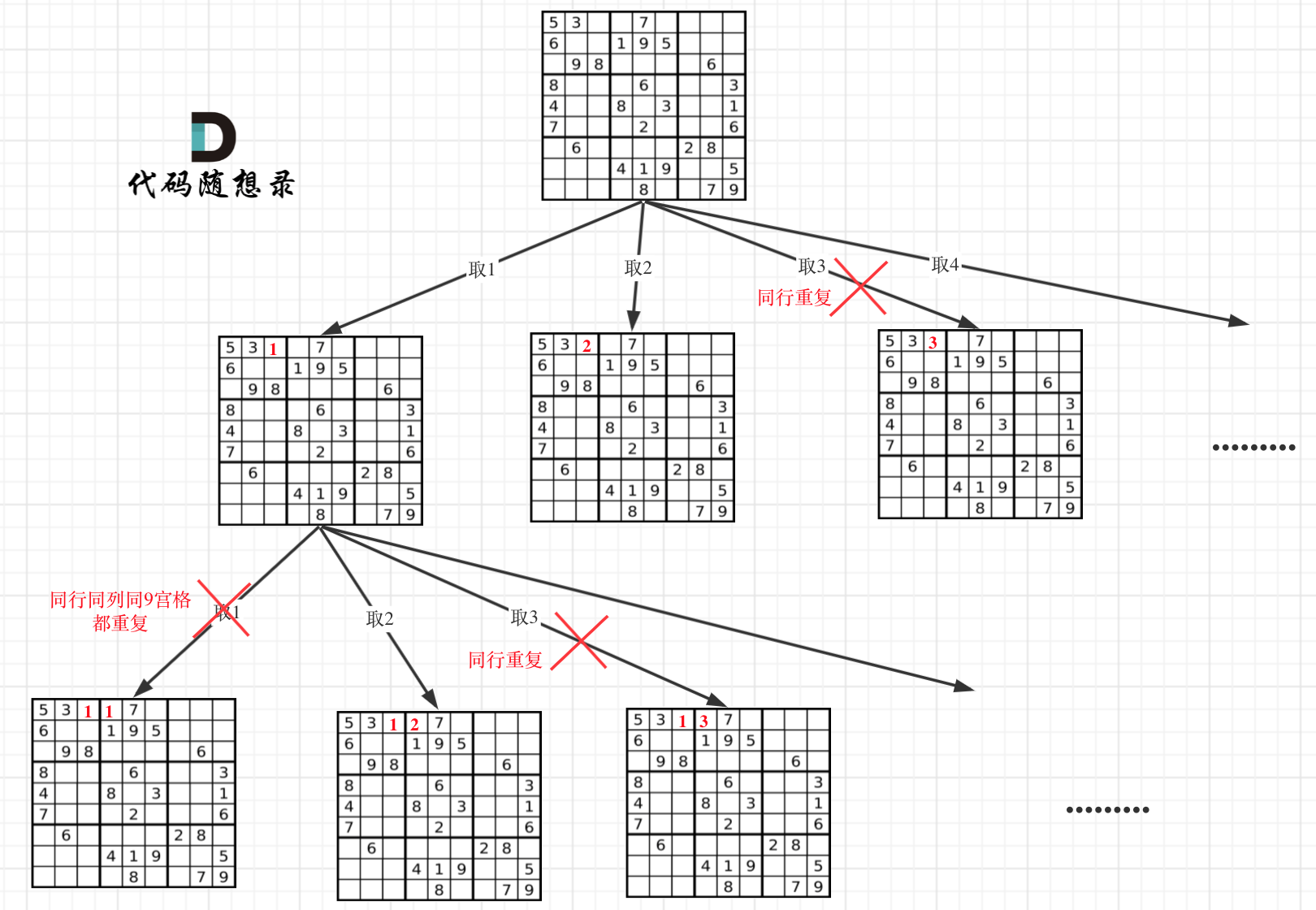
数独问题
一个数独的解法需遵循如下规则: 数字 1-9 在每一行只能出现一次。 数字 1-9 在每一列只能出现一次。 数字 1-9 在每一个以粗实线分隔的 3x3 宫内只能出现一次。 空白格用 ‘.’ 表示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 boolean backtrack (char [][] board,int i,int j) { int m=9 ,n=9 ; if (j==n){ return backtrack(board,i+1 ,0 ); } if (i==m){ return true ; } if (board[i][j] != '.' ){ return backtrack(board,i,j+1 ); } for (char ch='1' ;ch<='9' ;ch++){ if (!isValid(board,i,j,ch)) continue ; board[i][j]=ch; if (backtrack(board,i,j+1 )) return true ; board[i][j]='.' ; } return false ; } boolean isValid (char [][] board, int r, int c, char n) { for (int i=0 ;i<9 ;++i){ if (board[r][i]==n) return false ; if (board[i][c]==n) return false ; if (board[(r/3 )*3 +i/3 ][(c/3 )*3 +i%3 ]==n) return false ; } return true ; }
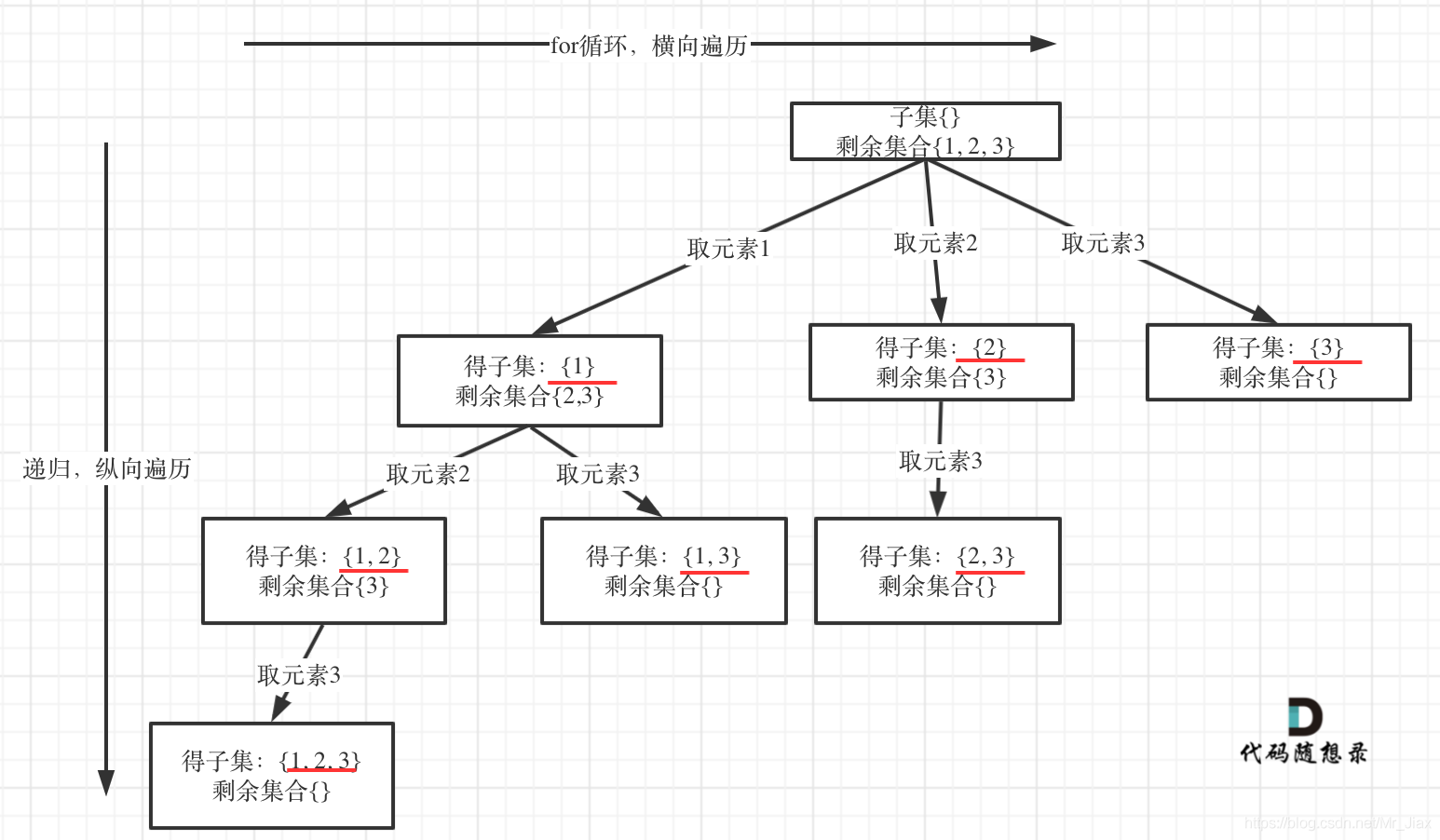
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
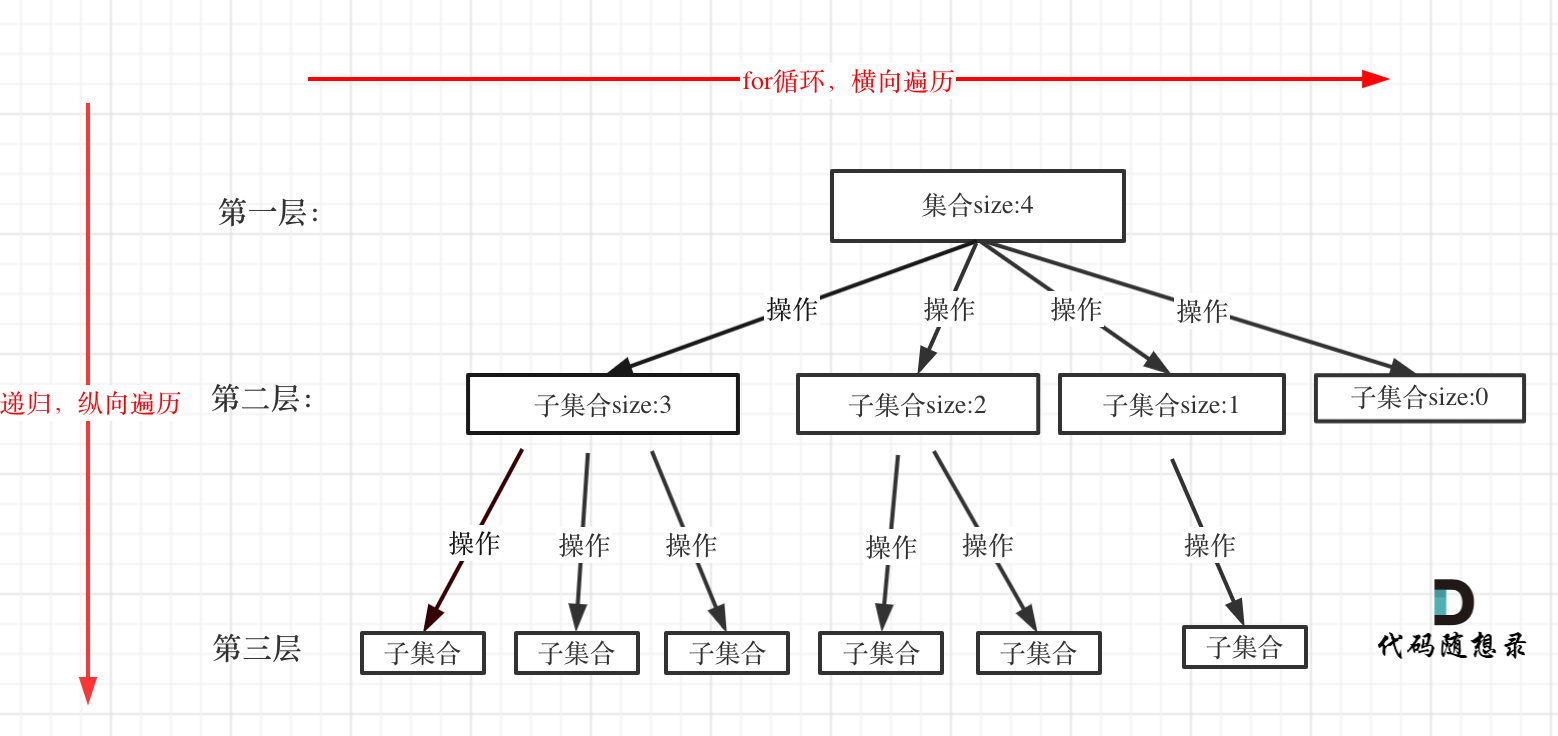
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution { public List<List<Integer>> subsets (int [] nums) { List<List<Integer>> res=new ArrayList <>(); res.add(new ArrayList <>()); for (int i=0 ;i<nums.length;++i){ int resSize=res.size(); for (int j=0 ;j<resSize;++j){ List<Integer> temp = new ArrayList <>(res.get(j)); temp.add(nums[i]); res.add(temp); } } return res; } }
递归法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution { List<List<Integer>> res=new ArrayList <>(); List<Integer> list = new ArrayList <>(); public List<List<Integer>> subsets (int [] nums) { backTrack(nums,0 ); return res; } private void backTrack (int [] nums, int cur) { res.add(new ArrayList <>(list)); for (int i=cur;i<nums.length;++i){ list.add(nums[i]); backTrack(nums,i+1 ); list.remove(list.size()-1 ); } } }
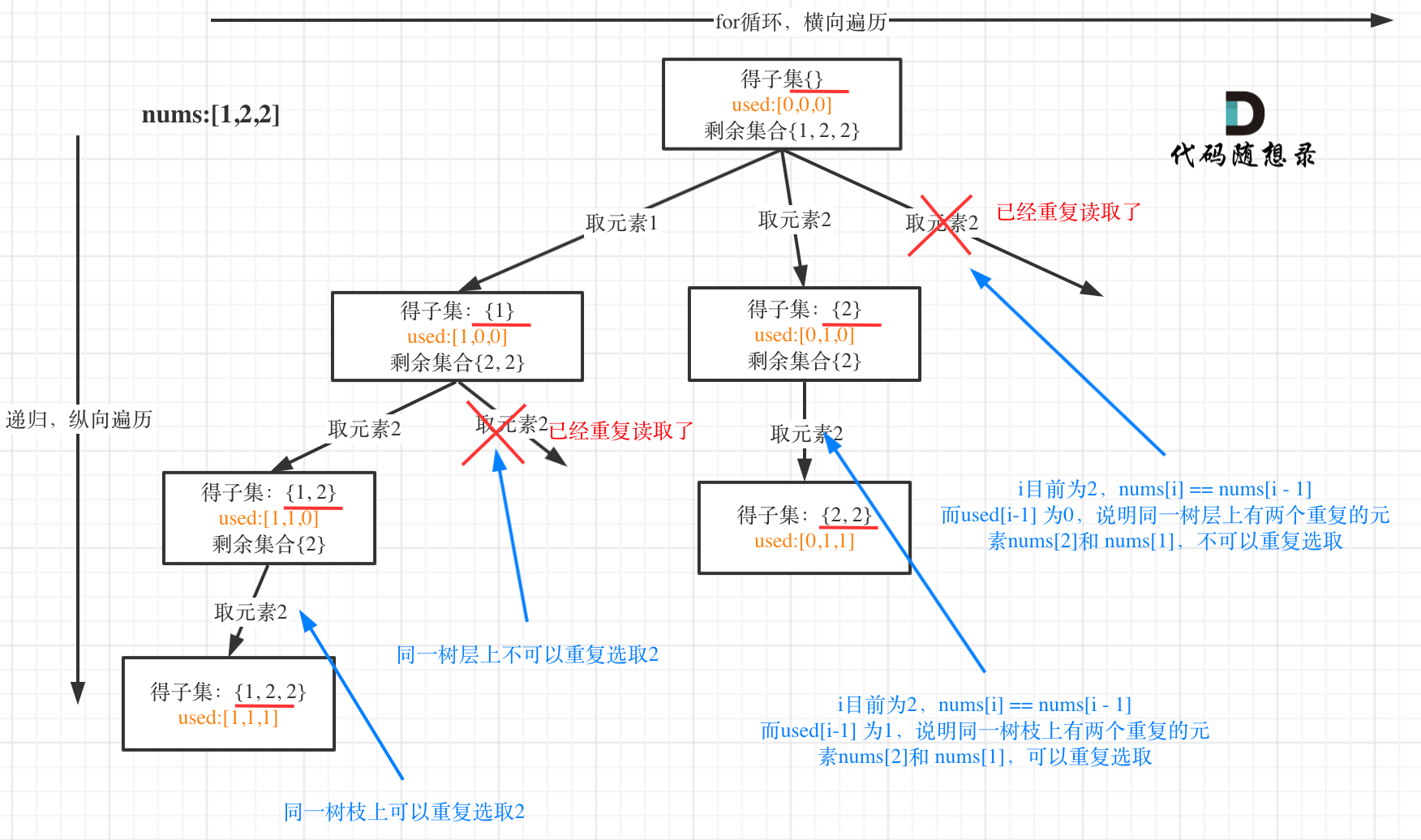
给你一个整数数组 nums ,其中可能包含重复元素,请你返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。返回的解集中,子集可以按 任意顺序 排列。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 class Solution { List<List<Integer>> res = new ArrayList <>(); List<Integer> path = new ArrayList <>(); public List<List<Integer>> subsetsWithDup (int [] nums) { boolean [] used = new boolean [nums.length]; Arrays.sort(nums); backTrack(nums,used,0 ); return res; } private void backTrack (int [] nums, boolean [] used, int cur) { res.add(new ArrayList <>(path)); for (int i=cur;i<nums.length;++i){ if (i>0 &&nums[i]==nums[i-1 ]&&used[i-1 ]==false ) continue ; path.add(nums[i]); used[i]=true ; backTrack(nums,used,i+1 ); used[i]=false ; path.remove(path.size()-1 ); } } } class Solution { List<List<Integer>> res = new ArrayList <>(); List<Integer> path = new ArrayList <>(); public List<List<Integer>> subsetsWithDup (int [] nums) { Arrays.sort(nums); backTrack(nums,0 ); return res; } private void backTrack (int [] nums, int cur) { res.add(new ArrayList <>(path)); for (int i=cur;i<nums.length;++i){ if (i>cur&&nums[i]==nums[i-1 ]) continue ; path.add(nums[i]); backTrack(nums,i+1 ); path.remove(path.size()-1 ); } } }
本题与子集II 的问题非常类似,但也有差别,因为在子集II 问题中我们可以对数组进行排序,所以我们可以使用i>cur&&nums[i]==nums[i-1] 来进行去重,但在本题中,我们无法对数组进行排序,所以只能使用Map 来对本层元素进行去重。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution { List<List<Integer>> res; List<Integer> path; public List<List<Integer>> findSubsequences (int [] nums) { res = new ArrayList <>(); path = new ArrayList <>(); backTrack(nums,0 ); System.out.println(res.size()); return res; } private void backTrack (int [] nums,int cur) { if (path.size()>1 ) res.add(new ArrayList <>(path)); Map<Integer,Integer> map = new HashMap <>(); for (int i=cur;i<nums.length;i++){ if ( map.getOrDefault( nums[i],0 ) >=1 ){ continue ; } if (path.size()>0 &&nums[i]<path.get(path.size()-1 )) continue ; map.put(nums[i],map.getOrDefault( nums[i],0 )+1 ); path.add(nums[i]); backTrack(nums,i+1 ); path.remove(path.size()-1 ); } } }
组合
给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。
你可以按 任何顺序 返回答案。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Solution { List<List<Integer>> res; List<Integer> temp; public List<List<Integer>> combine (int n, int k) { res=new ArrayList <>(); temp=new ArrayList <>(); backTrack(n,k,1 ); return res; } private void backTrack (int n,int k,int cur) { if (temp.size()==k){ res.add(new ArrayList <>(temp)); return ; } for (int i=cur;i<=n-(k-path.size())+1 ;++i){ temp.add(i); backTrack(n,k,i+1 ); temp.remove(temp.size()-1 ); } } }
给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。
candidates 中的 同一个 数字可以 无限制重复被选取 。如果至少一个数字的被选数量不同,则两种组合是不同的。
对于给定的输入,保证和为 target 的不同组合数少于 150 个。
什么时候使用 used 数组,什么时候使用 begin 变量
排列问题,讲究顺序(即 [2, 2, 3] 与 [2, 3, 2] 视为不同列表时),需要记录哪些数字已经使用过,此时用 used 数组;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution { List<List<Integer>> res; List<Integer> path; public List<List<Integer>> combinationSum (int [] candidates, int target) { res=new ArrayList <>(); path=new ArrayList <>(); Arrays.sort(candidates); backTrack(candidates,target,0 ); return res; } private void backTrack (int [] candidates,int target,int begin) { if (target<0 ) return ; if (target==0 ){ res.add(new ArrayList <>(path)); } for (int i=begin;i<candidates.length;++i){ if (target-candidates[i]>=0 ){ path.add(candidates[i]); backTrack(candidates,target-candidates[i],i); path.remove(path.size()-1 ); } else return ; } } }
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。
给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 class Solution { List<String> res=new ArrayList <>(); StringBuilder temp = new StringBuilder (); public List<String> letterCombinations (String digits) { if (digits.length()==0 ) return res; String[] numString = {"" , "" , "abc" , "def" , "ghi" , "jkl" , "mno" , "pqrs" , "tuv" , "wxyz" }; backTrack(digits,numString,0 ); return res; } private void backTrack (String digits,String[] numString, int begin) { if (temp.length()==digits.length()){ res.add(temp.toString()); return ; } String str= numString[digits.charAt(begin)-'0' ]; for (int i=0 ;i<str.length();++i){ temp.append(str.charAt(i)); backTrack(digits,numString,begin+1 ); temp.deleteCharAt(temp.length()-1 ); } } } class Solution { List<String> res=new ArrayList <>(); StringBuilder temp = new StringBuilder (); public List<String> letterCombinations (String digits) { if (digits.length()==0 ) return res; String[] numString = {"" , "" , "abc" , "def" , "ghi" , "jkl" , "mno" , "pqrs" , "tuv" , "wxyz" }; backTrack(digits,numString,0 ); return res; } private void backTrack (String digits,String[] numString, int begin) { if (temp.length()==digits.length()){ res.add(temp.toString()); return ; } for (int j=begin;j<digits.length();j++){ String str= numString[digits.charAt(begin)-'0' ]; for (int i=0 ;i<str.length();++i){ temp.append(str.charAt(i)); backTrack(digits,numString,j+1 ); temp.deleteCharAt(temp.length()-1 ); } } } }
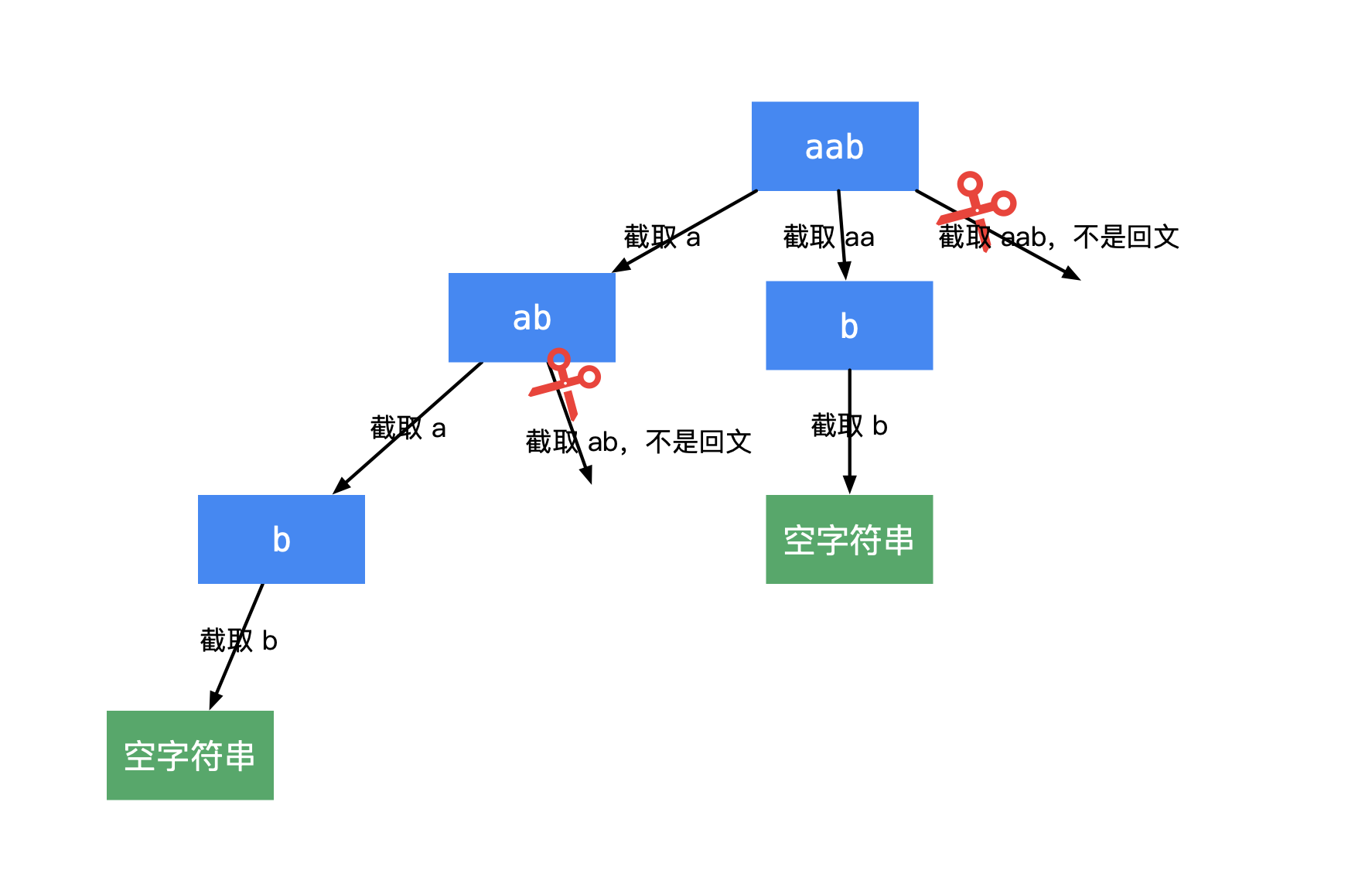
给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是 回文串 。返回 s 所有可能的分割方案。回文串 是正着读和反着读都一样的字符串。
用回溯算法解题时,我们应该首先考虑到回溯的第一层节点(选择列表)是什么 ,想清楚这个问题,那么后面的问题也就非常类似了。因为回溯的下一层只是上一层的一个子问题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Solution { List<List<String>> res=new ArrayList <>(); List<String> path=new ArrayList <>(); public List<List<String>> partition (String s) { backTrack(s,0 ); return res; } private void backTrack (String s,int begin) { if (begin>=s.length()){ res.add(new ArrayList <>(path)); } for (int i=begin;i<s.length();++i){ if (isValid(s,begin,i+1 )) path.add(s.substring(begin,i+1 )); else continue ; backTrack(s,i+1 ); path.remove(path.size()-1 ); } } private boolean isValid (String str,int begin,int end) { int len=end-begin; if (len==1 ) return true ; if (len==0 ) return false ; for (int i=begin,j=end-1 ;i<=j;++i,--j){ if (str.charAt(i)!=str.charAt(j)) return false ; } return true ; } }
复原IP地址
有效 IP 地址 正好由四个整数(每个整数位于 0 到 255 之间组成,且不能含有前导 0),整数之间用 ‘.’ 分隔。
例如:”0.1.2.201” 和 “192.168.1.1” 是 有效 IP 地址,但是 “0.011.255.245”、”192.168.1.312” 和 “192.168@1.1 “ 是 无效 IP 地址。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 class Solution { List<String> res=new ArrayList <>(); Deque<String> path = new ArrayDeque <>(); public List<String> restoreIpAddresses (String s) { int len=s.length(); if (len<4 ||len>12 ) return res; backTrack(s,len,0 ,0 ); return res; } private void backTrack (String s,int len,int splitCount, int begin) { if (begin==len){ if (splitCount==4 ){ res.add(String.join("." ,path)); } return ; } if (len-begin<(4 -splitCount)||(len-begin)>3 *(4 -splitCount)) return ; for (int i=0 ;i<3 ;i++){ if (begin+i>=len) break ; int ipSeg=judgeifIpSegment(s,begin,begin+i); if (ipSeg!=-1 ){ path.addLast(Integer.toString(ipSeg)); backTrack(s,len,splitCount+1 ,begin+i+1 ); path.removeLast(); } } } private int judgeifIpSegment (String s,int left,int right) { int len=right-left+1 ; if (len>1 &&s.charAt(left)=='0' ) return -1 ; int res=Integer.parseInt(s.substring(left,right+1 )); if (res>255 ) return -1 ; return res; } }
数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。
一眼dfs
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Solution { List<String> list = new ArrayList <>(); StringBuilder sb = new StringBuilder (); public List<String> generateParenthesis (int n) { dfs(n,n,"" ); return list; } private void dfs (int left,int right,String s) { if (left==0 &&right==0 ){ list.add(s); return ; } if (left>0 ){ dfs(left-1 ,right,s+"(" ); } if (right>left){ dfs(left,right-1 ,s+")" ); } } }
贪心算法 贪心算法(greedy algorithm [8] ,又称贪婪算法)是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,算法得到的是在某种意义上的局部最优解
利用贪心法求解的问题应具备如下2个特征:
贪心选择性质
一个问题的整体最优解可通过一系列局部的最优解的选择达到,并且每次的选择可以依赖以前作出的选择,但不依赖于后面要作出的选择。这就是贪心选择性质。对于一个具体问题,要确定它是否具有贪心选择性质,必须证明每一步所作的贪心选择最终导致问题的整体最优解,无后效性是指如果在某个阶段上过程的状态已知,则从此阶段以后过程的发展变化仅与此阶段的状态有关,而与过程在此阶段以前的阶段所经历过的状态无关。利用动态规划 方法求解多阶段决策过程问题,过程的状态必须具备无后效性
最优子结构性质
当一个问题的最优解包含其子问题的最优解时,称此问题具有最优子结构性质。问题的最优子结构性质是该问题可用贪心法求解的关键所在。在实际应用中,至于什么问题具有什么样的贪心选择性质是不确定的,需要具体问题具体分析
贪心法可以解决一些最优化 问题,如:求图 中的最小生成树 、求哈夫曼编码
假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。
对每个孩子 i,都有一个胃口值 g[i],这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼干 j,都有一个尺寸 s[j] 。如果 s[j] >= g[i],我们可以将这个饼干 j 分配给孩子 i ,这个孩子会得到满足。你的目标是尽可能满足越多数量的孩子,并输出这个最大数值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution { public int findContentChildren (int [] g, int [] s) { Arrays.sort(g); Arrays.sort(s); int res=0 ; int cookNum=s.length; int childNum=g.length; for (int i=0 ,j=0 ;i<cookNum&&j<childNum;i++,j++){ while (i<cookNum&&s[i]<g[j]) i++; if (i!=cookNum) res++; } return res; } }
如果连续数字之间的差严格地在正数和负数之间交替,则数字序列称为 摆动序列 。第一个差(如果存在的话)可能是正数或负数。仅有一个元素或者含两个不等元素的序列也视作摆动序列。
例如, [1, 7, 4, 9, 2, 5] 是一个 摆动序列 ,因为差值 (6, -3, 5, -7, 3) 是正负交替出现的。
相反,[1, 4, 7, 2, 5] 和 [1, 7, 4, 5, 5] 不是摆动序列,第一个序列是因为它的前两个差值都是正数,第二个序列是因为它的最后一个差值为零。
给你一个整数数组 nums ,返回 nums 中作为 摆动序列 的 最长子序列的长度 。
模拟法,需要特殊处理的只有摆动序列开始的元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution { public int wiggleMaxLength (int [] nums) { int res=1 ; int len=nums.length; int cur=0 ,pre=0 ; for (int i=1 ;i<len;++i){ cur=nums[i]-nums[i-1 ]; if (cur*pre<0 ||cur!=0 &&pre==0 ){ res++; pre=cur; } } return res; } }
给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 class Solution { public int maxSubArray (int [] nums) { int res=Integer.MIN_VALUE; int count=0 ; for (int i=0 ;i<nums.length;++i){ count=0 ; for (int j=i;j<nums.length;++j){ count+=nums[j]; res=count>res?count:res; } } return res; } } class Solution { public int maxSubArray (int [] nums) { int res=nums[0 ]; int count=0 ; for (int i=0 ;i<nums.length;++i){ count+=nums[i]; if (count>res) res=count; if (count<0 ) count=0 ; } return res; } } class Solution { public int maxSubArray (int [] nums) { int res=nums[0 ]; int [] dp = new int [nums.length]; dp[0 ]=res; for (int i=1 ;i<nums.length;++i){ dp[i]=Math.max(nums[i]+dp[i-1 ],nums[i]); if (dp[i]>res) res=dp[i]; } return res; } }
给你一个整数数组 prices ,其中 prices[i] 表示某支股票第 i 天的价格。
在每一天,你可以决定是否购买和/或出售股票。你在任何时候 最多 只能持有 一股 股票。你也可以先购买,然后在 同一天 出售。
返回你能获得的最大利润 。
既然可以当天买卖,那么就只需要累加大于0的差值。
1 2 3 4 5 6 7 8 9 10 class Solution { public int maxProfit (int [] prices) { int profit=0 ; for (int i=1 ;i<prices.length;++i){ int dif=prices[i]-prices[i-1 ]; if (dif>0 ) profit+=dif; } return profit; } }
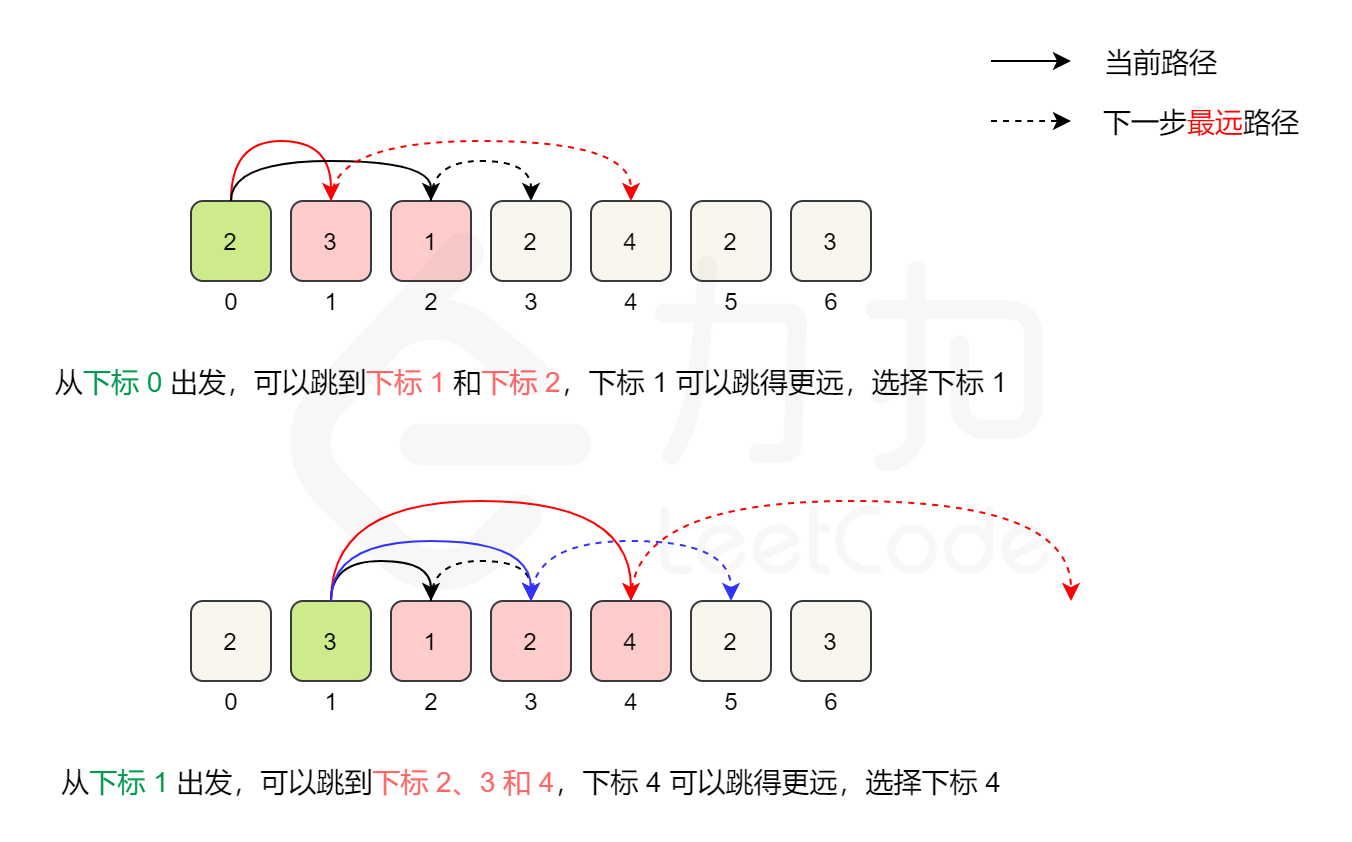
给定一个非负整数数组 nums ,你最初位于数组的 第一个下标 。
数组中的每个元素代表你在该位置可以跳跃的最大长度。
判断你是否能够到达最后一个下标。
nums[i] 表示可以跳到的最大的范围,但关键不在于能够跳几步,关键在于跳的范围,我们可以在循环中,不断更新我们能够跳到的最大的范围,如果这个范围达到了数组的长度,那么就表示我们能够跳到最后一步。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution { public boolean canJump (int [] nums) { int len=nums.length; int range=0 ; for (int i=0 ;i<=range;++i){ if (i+nums[i]>=len-1 ) return true ; else { range=Math.max(i+nums[i],range); } } return false ; } }
给你一个非负整数数组 nums ,你最初位于数组的第一个位置。
数组中的每个元素代表你在该位置可以跳跃的最大长度。
你的目标是使用最少的跳跃次数到达数组的最后一个位置。
假设你总是可以到达数组的最后一个位置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Solution { public int jump (int [] nums) { int len=nums.length; if (len==1 ) return 0 ; int maxRange=0 ; int range=0 ; int step=0 ; for (int i=0 ;i<len;++i){ maxRange=Math.max(maxRange,i+nums[i]); if (maxRange>=len-1 ) { return step+1 ; } if (i==range){ step++; range=maxRange; } } return step; } }
给你一个整数数组 nums 和一个整数 k ,按以下方法修改该数组:
选择某个下标 i 并将 nums[i] 替换为 -nums[i] 。
以这种方式修改数组后,返回数组 可能的最大和 。
在考虑问题时,不能先入为主,我们应该尽可能的判断到所有的情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution { public int largestSumAfterKNegations (int [] nums, int k) { Arrays.sort(nums); int len=nums.length; int sum=0 ; int minValue=Integer.MAX_VALUE; for (int i=0 ;i<len;++i){ if (nums[i]>0 )break ; if (nums[i]<0 &&k>0 ){ nums[i]=-nums[i]; k--; } } for (int i=0 ;i<len;++i){ sum+=nums[i]; if (minValue>nums[i]) minValue=nums[i]; } if (k%2 ==1 ){ sum-=2 *minValue; } return sum; } }
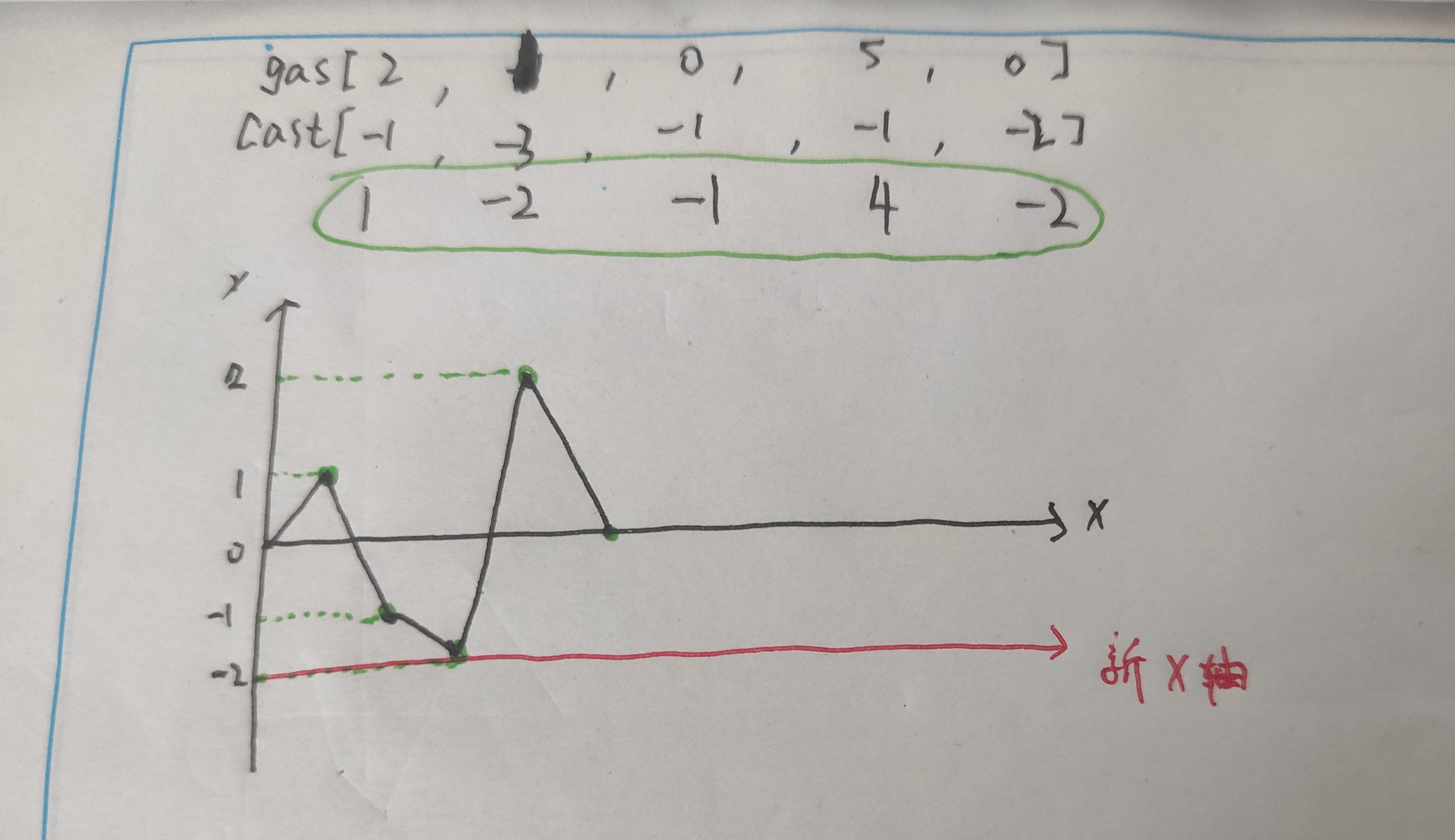
在一条环路上有 n 个加油站,其中第 i 个加油站有汽油 gas[i] 升。
你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i+1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发,开始时油箱为空。
给定两个整数数组 gas 和 cost ,如果你可以绕环路行驶一周,则返回出发时加油站的编号,否则返回 -1 。如果存在解,则 保证 它是 唯一 的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 class Solution { public int canCompleteCircuit (int [] gas, int [] cost) { int sum=0 ; int res=0 ; int min=0 ; for (int i=0 ;i<gas.length;++i){ gas[i]=gas[i]-cost[i]; sum+=gas[i]; } if (sum<0 ) return -1 ; sum=0 ; for (int i=0 ;i<gas.length;++i){ sum+=gas[i]; if (sum<min){ min=sum; res=i+1 ; } } return res; } } class Solution { public int canCompleteCircuit (int [] gas, int [] cost) { int n = gas.length; int cur_gas = 0 , min_gas = 0 , min_index = 0 ; for (int i = 0 ; i < n; i++){ cur_gas += gas[i] - cost[i]; if (cur_gas < min_gas){ min_gas = cur_gas; min_index = i + 1 ; } } return cur_gas < 0 ? -1 : min_index; } }
在柠檬水摊上,每一杯柠檬水的售价为 5 美元。顾客排队购买你的产品,(按账单 bills 支付的顺序)一次购买一杯。每位顾客只买一杯柠檬水,然后向你付 5 美元、10 美元或 20 美元。你必须给每个顾客正确找零,也就是说净交易是每位顾客向你支付 5 美元。注意,一开始你手头没有任何零钱。给你一个整数数组 bills ,其中 bills[i] 是第 i 位顾客付的账。如果你能给每位顾客正确找零,返回 true ,否则返回 false 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution { public boolean lemonadeChange (int [] bills) { int len= bills.length; int fiveNum=0 ,tenNum=0 ; for (int i=0 ;i<len;++i){ if (bills[i]==5 ){ fiveNum++; } else if (bills[i]==10 ){ tenNum++; fiveNum--; if (fiveNum<0 ) return false ; } else if (bills[i]==20 ){ if (tenNum-1 >=0 &&fiveNum-1 >=0 ){ tenNum--; fiveNum--; }else if (fiveNum-3 >=0 ){ fiveNum-=3 ; } else return false ; } } return true ; } }
假设有打乱顺序的一群人站成一个队列,数组 people 表示队列中一些人的属性(不一定按顺序)。每个 people[i] = [hi, ki] 表示第 i 个人的身高为 hi ,前面 正好 有 ki 个身高大于或等于 hi 的人。
请你重新构造并返回输入数组 people 所表示的队列。返回的队列应该格式化为数组 queue ,其中 queue[j] = [hj, kj] 是队列中第 j 个人的属性(queue[0] 是排在队列前面的人)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution { public int [][] reconstructQueue(int [][] people) { Arrays.sort(people,(o1,o2)->{ if (o1[0 ]==o2[0 ]) return o1[1 ]-o2[1 ]; return o2[0 ]-o1[0 ]; }); LinkedList<int []> que = new LinkedList <>(); int [][] res = new int [people.length][2 ]; for (int [] p: people){ que.add(p[1 ],p); } return que.toArray(new int [people.length][2 ]); } }
有一些球形气球贴在一堵用 XY 平面表示的墙面上。墙面上的气球记录在整数数组 points ,其中points[i] = [xstart, xend] 表示水平直径在 xstart 和 xend之间的气球。你不知道气球的确切 y 坐标。
一支弓箭可以沿着 x 轴从不同点 完全垂直 地射出。在坐标 x 处射出一支箭,若有一个气球的直径的开始和结束坐标为 xstart,xend, 且满足 xstart ≤ x ≤ xend,则该气球会被 引爆 。可以射出的弓箭的数量 没有限制 。 弓箭一旦被射出之后,可以无限地前进。
给你一个数组 points ,返回引爆所有气球所必须射出的 最小 弓箭数 。
这个题本质上还是求得最大不重合区间的总个数(包括端点也不能重合)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 class Solution { public int findMinArrowShots (int [][] points) { Arrays.sort(points,Comparator.comparingInt(a->a[0 ])); int count=1 ; for (int i=1 ;i<points.length;++i){ if (points[i][0 ] > points[i - 1 ][1 ]) { count++; } else { points[i][1 ] = Math.min(points[i][1 ],points[i - 1 ][1 ]); } } return count; } } class Solution { public int findMinArrowShots (int [][] points) { int n = points.length; Arrays.sort(points, (a, b) -> { return Integer.compare(a[1 ],b[1 ]); }); int count = 1 ; int end = points[0 ][1 ]; for (int [] point : points) { if (point[0 ] > end) { count++; end = point[1 ]; } } return count; } }
题目表述:
给定一个区间的集合 intervals ,其中 intervals[i] = [starti, endi] 。返回 需要移除区间的最小数量,使剩余区间互不重叠 。
参考题解:
首先看一下官解,官解这回非常给力,解法一动态规划和解法二贪心一定要看一下。
关于解法二贪心算法的合理性,这里作一下补充。其实这里的难点在于理解“为什么是按照右端点排序而不是左端点排序”。
#### 关于为什么是按照区间右端点排序?预定会议的一个问题,给你若干时间的会议,然后去预定会议,那么能够预定的最大的会议数量是多少?核心在于我们要找到最大不重叠区间的个数。 如果我们把本题的区间看成是会议,那么按照右端点排序,我们一定能够找到一个最先结束的会议,而这个会议一定是我们需要添加到最终结果的的首个会议。(这个不难贪心得到,因为这样能够给后面预留的时间更长)。
#### 关于为什么是不能按照区间左端点排序?区间看成是会议,如果“按照左端点排序,我们一定能够找到一个最先开始的会议”,但是最先开始的会议,不一定最先结束。。举个例子:
1 2 3 4 >|_________| 区间a |___| 区间b |__| 区间c |______| 区间d
区间a是最先开始的,如果我们采用区间a作为放入最大不重叠区间的首个区间,那么后面我们只能采用区间d作为第二个放入最大不重叠区间的区间,但这样的话,最大不重叠区间的数量为2。但是如果我们采用区间b作为放入最大不重叠区间的首个区间,那么最大不重叠区间的数量为3,因为区间b是最先结束的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 class Solution { public int eraseOverlapIntervals (int [][] intervals) { Arrays.sort(intervals,(a,b)->{ if (a[0 ]==b[0 ])return a[1 ]-b[1 ]; else return a[0 ]-b[0 ]; }); int count=0 ; for (int i=1 ;i<intervals.length;++i){ if (intervals[i][0 ]>=intervals[i-1 ][1 ]) continue ; else { intervals[i][1 ] = Math.min(intervals[i][1 ],intervals[i-1 ][1 ]); count++; } } return count; } } class Solution { public int eraseOverlapIntervals (int [][] intervals) { Arrays.sort(intervals,(a,b)->{ return a[1 ]-b[1 ]; }); int count=1 ; int end=intervals[0 ][1 ]; for (int i=1 ;i<intervals.length;++i){ if (intervals[i][0 ]>=end){ end=intervals[i][1 ]; count++; } } return intervals.length - count; } }
给你一个数组 events,其中 events[i] = [startDayi, endDayi] ,表示会议 i 开始于 startDayi ,结束于 endDayi 。
你可以在满足 startDayi <= d <= endDayi 中的任意一天 d 参加会议 i 。注意,一天只能参加一个会议。
请你返回你可以参加的 最大 会议数目。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 class Solution { public int maxEvents (int [][] events) { Arrays.sort(events,(a,b)->{ if (a[1 ]!=b[1 ]) return a[1 ]-b[1 ]; else return a[0 ]-b[0 ]; }); int k=1 ; HashSet<Integer> set=new HashSet <>(); for (int [] event : events){ int i=event[0 ]; if (event[0 ]<k) i=k; for (i=event[0 ];i<=event[1 ];++i){ if (set.add(i)){ k=i; break ; } } } return set.size(); } } class Solution { public int maxEvents (int [][] events) { int n = events.length; Arrays.sort(events, new Comparator <int []>() { @Override public int compare (int [] o1, int [] o2) { return o1[0 ] - o2[0 ]; } }); PriorityQueue<Integer> pq = new PriorityQueue <>(); int res = 0 ; int currDay = 1 ; int i = 0 ; while (i < n || !pq.isEmpty()) { while (i < n && events[i][0 ] == currDay) { pq.add(events[i][1 ]); i++; } while (!pq.isEmpty() && pq.peek() < currDay) { pq.remove(); } if (!pq.isEmpty()) { pq.remove(); res++; } currDay++; } return res; } }
字符串 S 由小写字母组成。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。返回一个表示每个字符串片段的长度的列表。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 class Solution { public List<Integer> partitionLabels (String s) { int [] freq = new int [26 ]; int [] curSta = new int [26 ]; int len = s.length(); for (int i=0 ;i<len;++i){ freq[s.charAt(i)-'a' ]++; } int part=0 ; List<Integer> res = new ArrayList <>(); for (int i=0 ;i<len;++i){ char c = s.charAt(i); curSta[c-'a' ]++; part++; if (check(curSta,freq)){ res.add(part); part=0 ; } } return res; } private boolean check (int [] curSta,int []freq) { for (int i=0 ;i<26 ;++i){ if (curSta[i]==0 ) continue ; if (curSta[i]!=freq[i]) return false ; } return true ; } } class Solution { public List<Integer> partitionLabels (String s) { int len = s.length(); int [] lastIndex = new int [26 ]; char [] chars = s.toCharArray(); List<Integer> res = new ArrayList <>(); for (int i=0 ;i<len;++i){ lastIndex[chars[i]-'a' ]=i; } int max=0 ; int part=0 ; for (int i=0 ;i<len;++i){ part++; if (max<lastIndex[chars[i]-'a' ]){ max=lastIndex[chars[i]-'a' ]; } if (i==max){ res.add(part); part=0 ; } } return res; } }
给你一个长度为 n 的整数数组 nums ,返回使所有数组元素相等需要的最少移动数。
在一步操作中,你可以使数组中的一个元素加 1 或者减 1 。
1 2 3 4 5 >输入:nums = [1,2,3] >输出:2 >解释: >只需要两步操作(每步操作指南使一个元素加 1 或减 1): >[1,2,3] => [2,2,3] => [2,2,2]
1 2 >输入:nums = [1,10,2,9] >输出:16
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Solution { public int minMoves2 (int [] nums) { Arrays.sort(nums); int res=0 ; for (int i=0 ,j=nums.length-1 ;i<=j;i++,j--){ res+=nums[j]-nums[i]; } return res; } }
以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] = [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution { public int [][] merge(int [][] intervals) { List<int []> res = new ArrayList <>(); Arrays.sort(intervals,(a,b)->{ if (a[0 ]!=b[0 ]) return a[0 ]-b[0 ]; return a[1 ]-b[1 ]; }); int [] temp = new int [2 ]; temp[0 ]=intervals[0 ][0 ]; temp[1 ]=intervals[0 ][1 ]; for (int i=1 ;i<intervals.length;++i){ if (intervals[i][0 ]<=temp[1 ]){ if (temp[1 ]<intervals[i][1 ]) temp[1 ]=intervals[i][1 ]; }else { res.add(new int []{temp[0 ],temp[1 ]}); temp[0 ]=intervals[i][0 ]; temp[1 ]=intervals[i][1 ]; } } res.add(new int []{temp[0 ],temp[1 ]}); return res.toArray(new int [res.size()][2 ]); } }
当且仅当每个相邻位数上的数字 x 和 y 满足 x <= y 时,我们称这个整数是单调递增的。
给定一个整数 n ,返回 小于或等于 n 的最大数字,且数字呈 单调递增 。
示例 1:
示例 2:
示例 3:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution { public int monotoneIncreasingDigits (int n) { String s = String.valueOf(n); int length=s.length(); char [] chars = s.toCharArray(); int flag=length; for (int i=length-1 ;i>=1 ;i--){ if (chars[i]<chars[i-1 ]){ chars[i-1 ]--; flag=i; } } for (int i=flag;i<length;++i){ chars[i]='9' ; } return Integer.parseInt(new String (chars)); } }
给定一个整数数组 prices,其中 prices[i]表示第 i 天的股票价格 ;整数 fee 代表了交易股票的手续费用。
你可以无限次地完成交易,但是你每笔交易都需要付手续费。如果你已经购买了一个股票,在卖出它之前你就不能再继续购买股票了。
返回获得利润的最大值。
注意:这里的一笔交易指买入持有并卖出股票的整个过程,每笔交易你只需要为支付一次手续费。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution { public int maxProfit (int [] prices, int fee) { int len=prices.length; int [][]dp = new int [prices.length][2 ]; dp[0 ][0 ]-=prices[0 ]; for (int i=1 ;i<len;++i){ dp[i][0 ]=Math.max(dp[i-1 ][0 ],dp[i-1 ][1 ]-prices[i]); dp[i][1 ]=Math.max(dp[i-1 ][1 ],dp[i-1 ][0 ]+prices[i]-fee); } return Math.max(dp[len-1 ][0 ],dp[len-1 ][1 ]); } }
动态规划 不同路径 I 一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。
问总共有多少条不同的路径?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution { public int uniquePaths (int m, int n) { int [][] dp = new int [m][n]; for (int i = 0 ; i < n; i++) dp[0 ][i] = 1 ; for (int i = 0 ; i < m; i++) dp[i][0 ] = 1 ; for (int i = 1 ; i < m; i++) { for (int j = 1 ; j < n; j++) { dp[i][j] = dp[i - 1 ][j] + dp[i][j - 1 ]; } } return dp[m - 1 ][n - 1 ]; } } class Solution { public int uniquePaths (int m, int n) { int [] dp =new int [n]; Arrays.fill(dp,1 ); for (int i=1 ;i<m;++i){ for (int j=1 ;j<n;++j){ dp[j] += dp[j-1 ]; } } return dp[n-1 ]; } }
动态规划的题目分为两大类,一种是求最优解类,典型问题是背包问题,另一种就是计数类,比如这里的统计方案数的问题,它们都存在一定的递推性质。前者的递推性质还有一个名字,叫做 「最优子结构」 ——即当前问题的最优解取决于子问题的最优解,后者类似,当前问题的方案数取决于子问题的方案数。所以在遇到求方案数的问题时,我们可以往动态规划的方向考虑
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution { public int uniquePathsWithObstacles (int [][] obstacleGrid) { int m=obstacleGrid.length; int n=obstacleGrid[0 ].length; int [][] dp = new int [m][n]; for (int i=0 ;i<n;++i){ if (obstacleGrid[0 ][i] == 0 ){ dp[0 ][i]=1 ; }else break ; } for (int i=0 ;i<m;++i){ if (obstacleGrid[i][0 ]==0 ) dp[i][0 ]=1 ; else break ; } for (int i = 1 ; i < m; i++) { for (int j = 1 ; j < n; j++) { if (obstacleGrid[i][j]==1 ) continue ; dp[i][j] = dp[i - 1 ][j] + dp[i][j - 1 ]; } } return dp[m - 1 ][n - 1 ]; } }
给你一个非负整数数组 nums ,你最初位于数组的第一个位置。
数组中的每个元素代表你在该位置可以跳跃的最大长度。
你的目标是使用最少的跳跃次数到达数组的最后一个位置。
假设你总是可以到达数组的最后一个位置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution { public int jump (int [] nums) { int n=nums.length; if (n<2 ) return n-1 ; int []dp = new int [n]; dp[0 ]=0 ;dp[1 ]=1 ; for (int i=2 ;i<n;++i){ dp[i]=n; } for (int i=0 ;i<n;++i){ int range = i+nums[i]; for (int j=i;j<n;++j){ if (j<=range) dp[j] = Math.min(dp[j],dp[i]+1 ); else break ; } } return dp[n-1 ]; } }
给定一个包含非负整数的 *m* x *n* 网格 grid ,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小。
说明: 每次只能向下或者向右移动一步。
一眼dp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution { public int minPathSum (int [][] grid) { int m=grid.length; int n=grid[0 ].length; int [][] dp=new int [m][n]; int sum=0 ; for (int i=0 ;i<n;++i) { sum+=grid[0 ][i]; dp[0 ][i]=sum; } sum=0 ; for (int i=0 ;i<m;++i) { sum+=grid[i][0 ]; dp[i][0 ]=sum; } for (int i=1 ;i<m;++i){ for (int j=1 ;j<n;++j){ dp[i][j] = Math.min(dp[i][j-1 ],dp[i-1 ][j]) + grid[i][j]; } } return dp[m-1 ][n-1 ]; } }
将一个给定字符串 s 根据给定的行数 numRows ,以从上往下、从左到右进行 Z 字形排列。
比如输入字符串为 “PAYPALISHIRING” 行数为 3 时,排列如下:
P A H N
请你实现这个将字符串进行指定行数变换的函数:
string convert(string s, int numRows);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution { public String convert (String s, int numRows) { int len= s.length(); if (numRows==1 ) return s; ArrayList<Character>[] list= new ArrayList [numRows]; for (int i=0 ;i<numRows;++i){ list[i]=new ArrayList <>(); } for (int i=0 ;i<len;++i){ int index = getindex(numRows,i); list[index].add(s.charAt(i)); } StringBuilder sb = new StringBuilder (); for (int i=0 ;i<numRows;++i){ for (char c : list[i]){ sb.append(c); } } return sb.toString(); } private int getindex (int numRows,int i) { int k=i%(2 *numRows-2 ); if (k>=numRows){ k=2 *numRows-2 -k; } return k; } }
给你一个整数数组 nums 和一个整数 target 。
向数组中的每个整数前添加 ‘+’ 或 ‘-‘ ,然后串联起所有整数,可以构造一个 表达式 :
例如,nums = [2, 1] ,可以在 2 之前添加 ‘+’ ,在 1 之前添加 ‘-‘ ,然后串联起来得到表达式 “+2-1” 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution { int res=0 ; public int findTargetSumWays (int [] nums, int target) { backtrace(nums,target,0 ,0 ); return res; } private void backtrace (int [] nums, int tar,int sum,int n) { if (n==nums.length){ if (sum==tar) res++; return ; } backtrace(nums,tar,sum+nums[n],n+1 ); backtrace(nums,tar,sum-nums[n],n+1 ); } }